♻️ Tools
Replicate Blog
2 min read
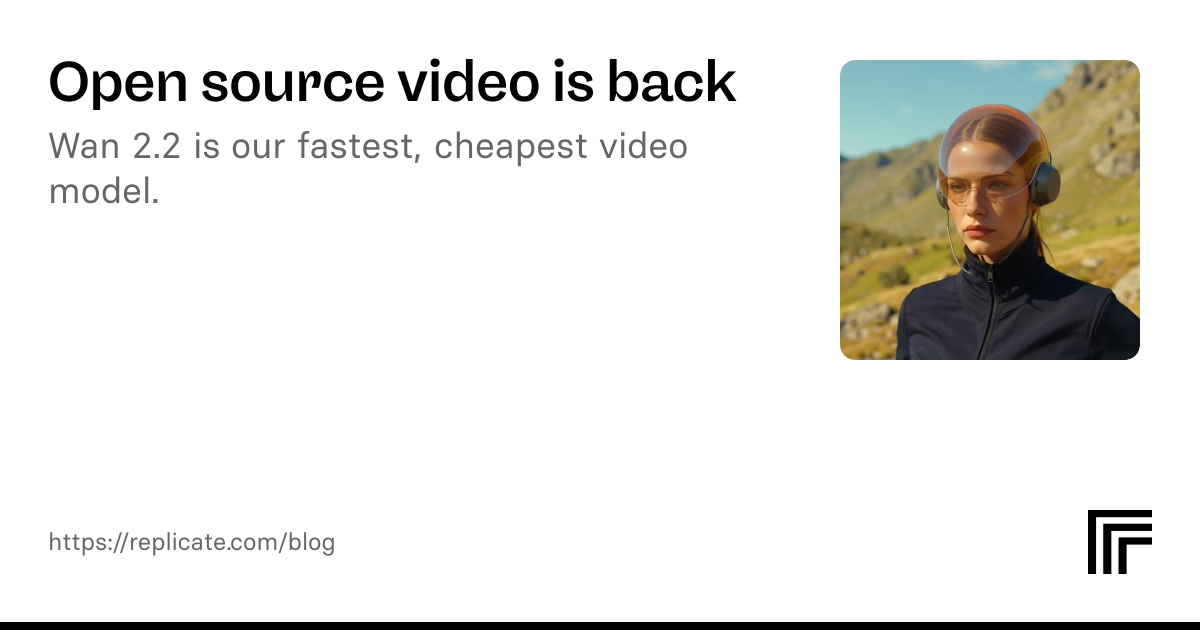
Open source video is back
Wan 2.2 is our fastest, cheapest video model.
Wan 2.2 is our fastest, cheapest video model.
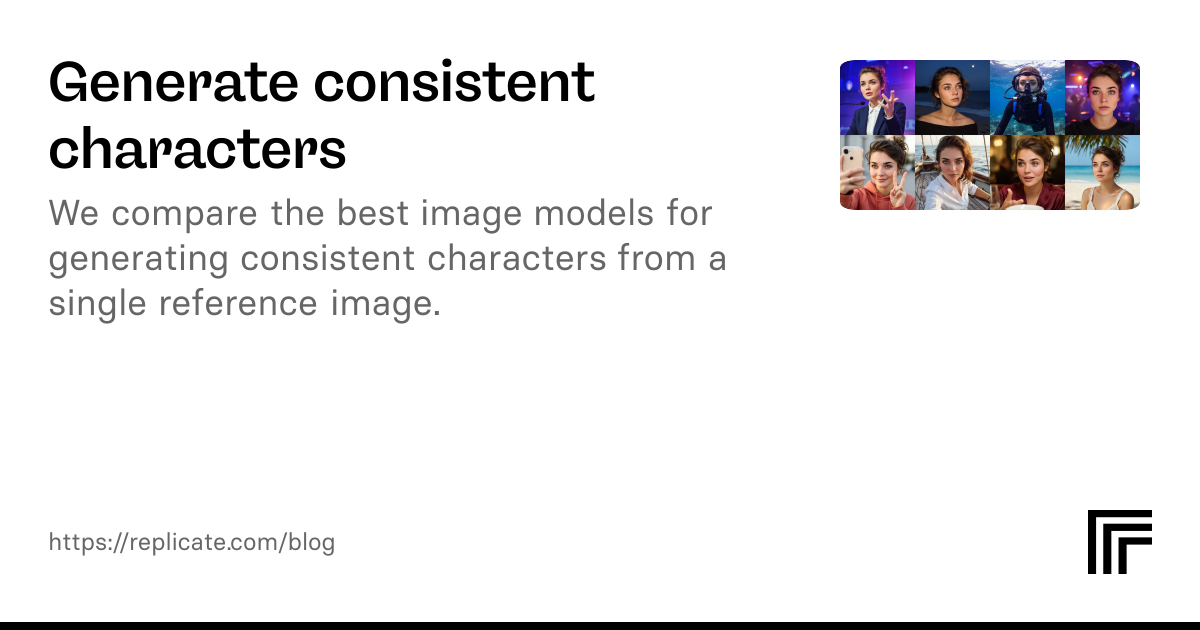
We compare the best image models for generating consistent characters from a single reference image.
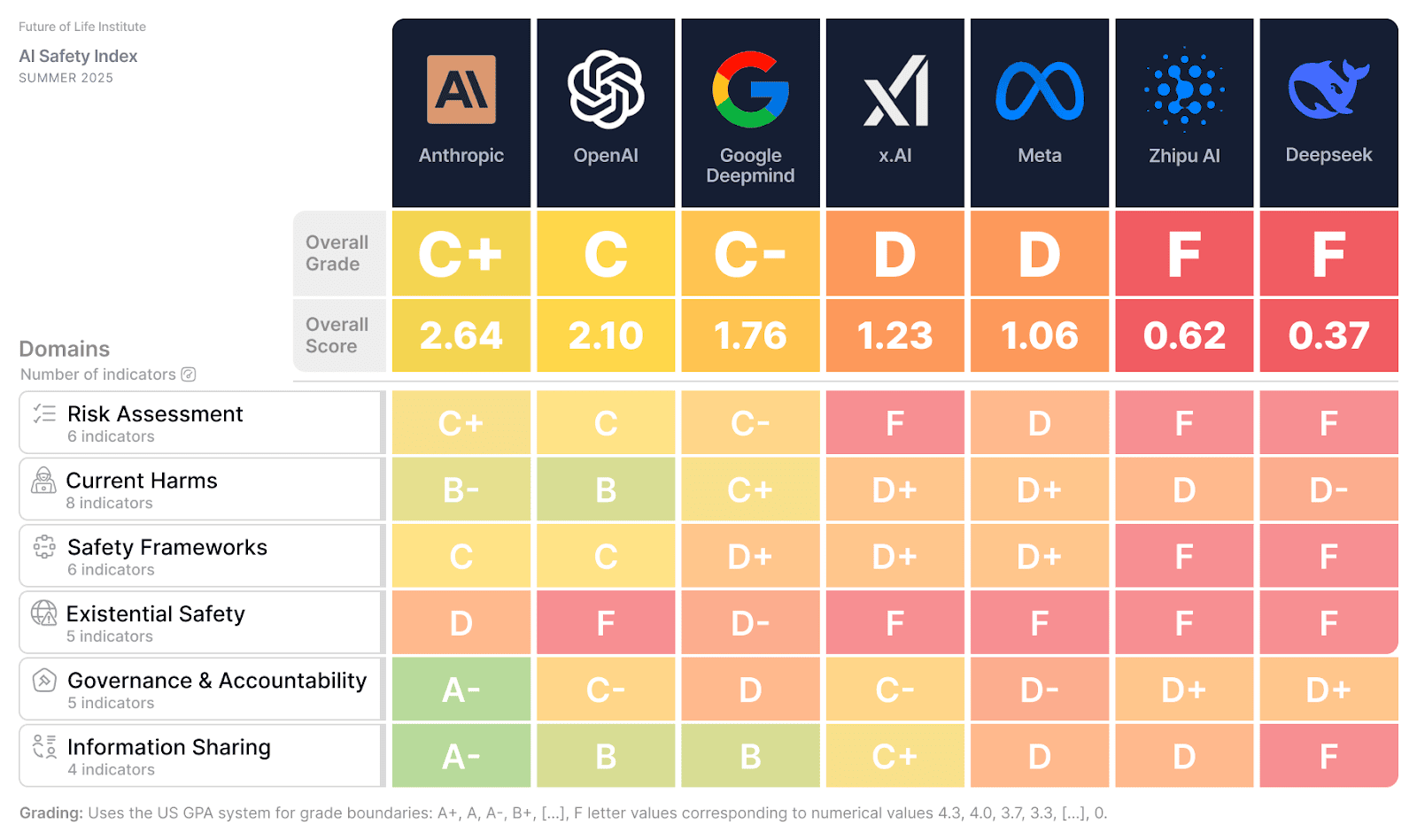
The Future of Life Institute’s 2025 summer update to its AI Safety Index shows some companies making incremental progress, but dangerous gaps remain in key categories such as risk assessment…

We've partnered with Bria to bring a suite of commercial-grade image generation and editing models to Replicate. Built entirely on licensed data, Bria’s tools are designed for enterprises and developers…
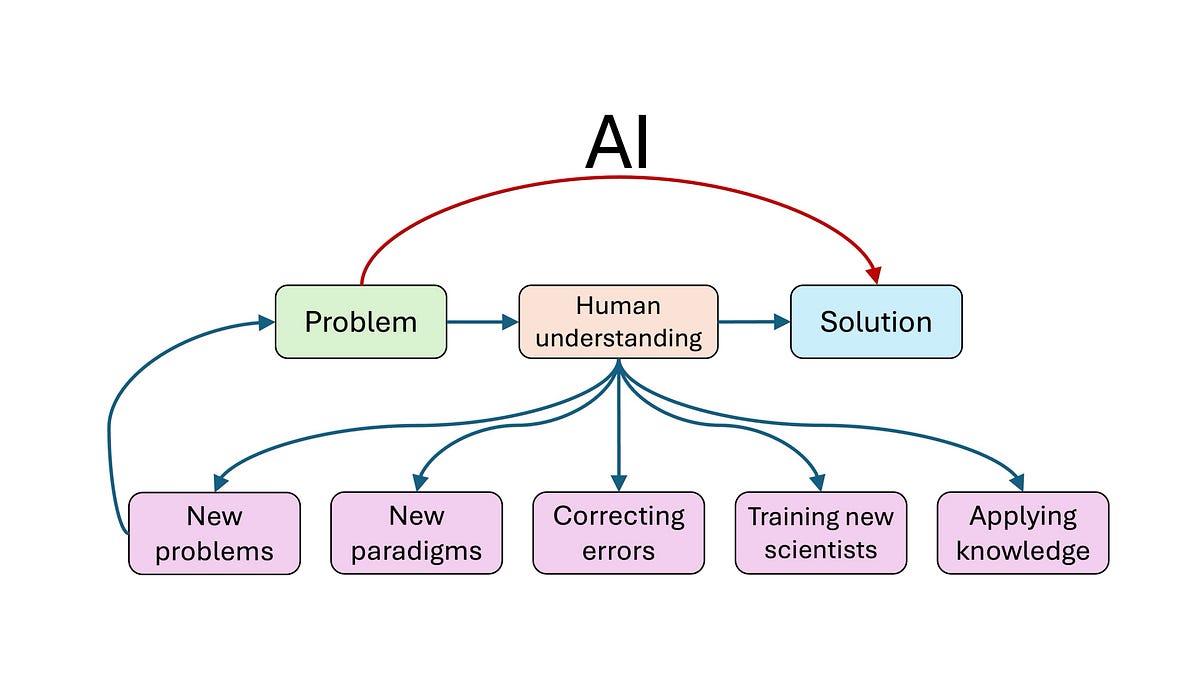
Confronting the production-progress paradox
![How we optimized FLUX.1 Kontext [dev]](https://replicate.com/blog/flux-kontext-optimization.png)
A deep-dive into the Taylor Seer optimization technique

It's hard keeping up with every new video model. In this post we'll help you pick the best one for your needs.

× Predicting Ego-centric Video from human Actions (PEVA) . Given past video frames and an action specifying a desired change in 3D pose, PEVA predicts the next video frame. Our…
We hosted a hackathon with BFL for FLUX.1 Kontext. Here were the winners.

ByteDance introduces Astra, an innovative dual-model architecture revolutionizing robot navigation in complex indoor environments. The post ByteDance Introduces Astra: A Dual-Model Architecture for Autonomous Robot Navigation first appeared on Synced…
MIT introduces SEAL, a framework enabling large language models to self-edit and update their weights via reinforcement learning. The post MIT Researchers Unveil “SEAL”: A New Step Towards Self-Improving AI…

"Automated failure attribution" is a crucial component in the development lifecycle of Multi-Agent systems. It has the potential to transform the challenge of identifying "what went wrong and who is…

Learn expert prompting techniques to create stunning videos with Google's Veo 3.

With every platform shift, we want to measure the growth but we’re confused about what to measure. That’s partly a problem of data and definitions, but it’s really a question…

We're sharing our experiments and tips on Google's new Veo 3 model.

"In projecting language back as the model for thought, we lose sight of the tacit embodied understanding that undergirds our intelligence." –Terry Winograd The recent successes of generative AI models…

FLUX.1 Kontext is everywhere - see what folks are cooking.
This is how to get the most from Black Forest Labs' new image editing model.

By combining State-Space Models (SSMs) for efficient long-range dependency modeling with dense local attention for coherence, and using training strategies like diffusion forcing and frame local attention, researchers from Adobe…

Generative AI chatbots might be a life-changing transformation in the nature of computing, that can replace all software, but so far, most of its users only pick it up every…
Google's flagship image generation model, Imagen 4, is now available for you to try on Replicate. Create images with fine detail, versatile styles, and improved typography.

OpenAI's latest models are now available on Replicate, including GPT-4.1, GPT-4o, and the o-series.

NVIDIA H100 GPUs are here, with better performance and lower cost.

A newly released 14-page technical paper from the team behind DeepSeek-V3, with DeepSeek CEO Wenfeng Liang as a co-author, sheds light on the “Scaling Challenges and Reflections on Hardware for…