In this article, you will learn how to design, scale, and secure tool calling in AI agents so that the layer connecting model reasoning to real-world action holds up in production.
Topics we will cover include:
- How the tool calling protocol separates model reasoning from deterministic execution, and why that boundary matters.
- How to write tool definitions, error handling, and parallelization strategies that stay reliable as your agent scales.
- How to manage tool catalog size, secure agentic systems, and evaluate tool calls beyond end-to-end task success.
Introduction
Most AI agent failures do not trace back to bad reasoning. The model understands the task, then calls the wrong tool, passes malformed arguments, gets back an unhandled error, and produces a wrong answer anyway. The reasoning layer gets the attention; the tool layer is where production incidents actually happen.
Tool calling — also called function calling — is what bridges a language model’s reasoning to real-world action. Without it, agents are capped by training data: no live queries, no external systems, no side effects. With it, an agent can search the web, call APIs, run code, retrieve documents, and trigger transactions in any system that exposes an interface.
Getting this right means understanding the full stack, not just the happy path. This article covers:
- Understanding the tool calling protocol and why the execution boundary matters
- Writing definitions and error handling that hold up in production
- Scaling tool catalogs and parallelizing calls without sacrificing accuracy
- Securing agentic systems and evaluating beyond end-to-end task success
Each step covers when the concept applies, what trade-offs it carries, and what goes wrong when you skip it.
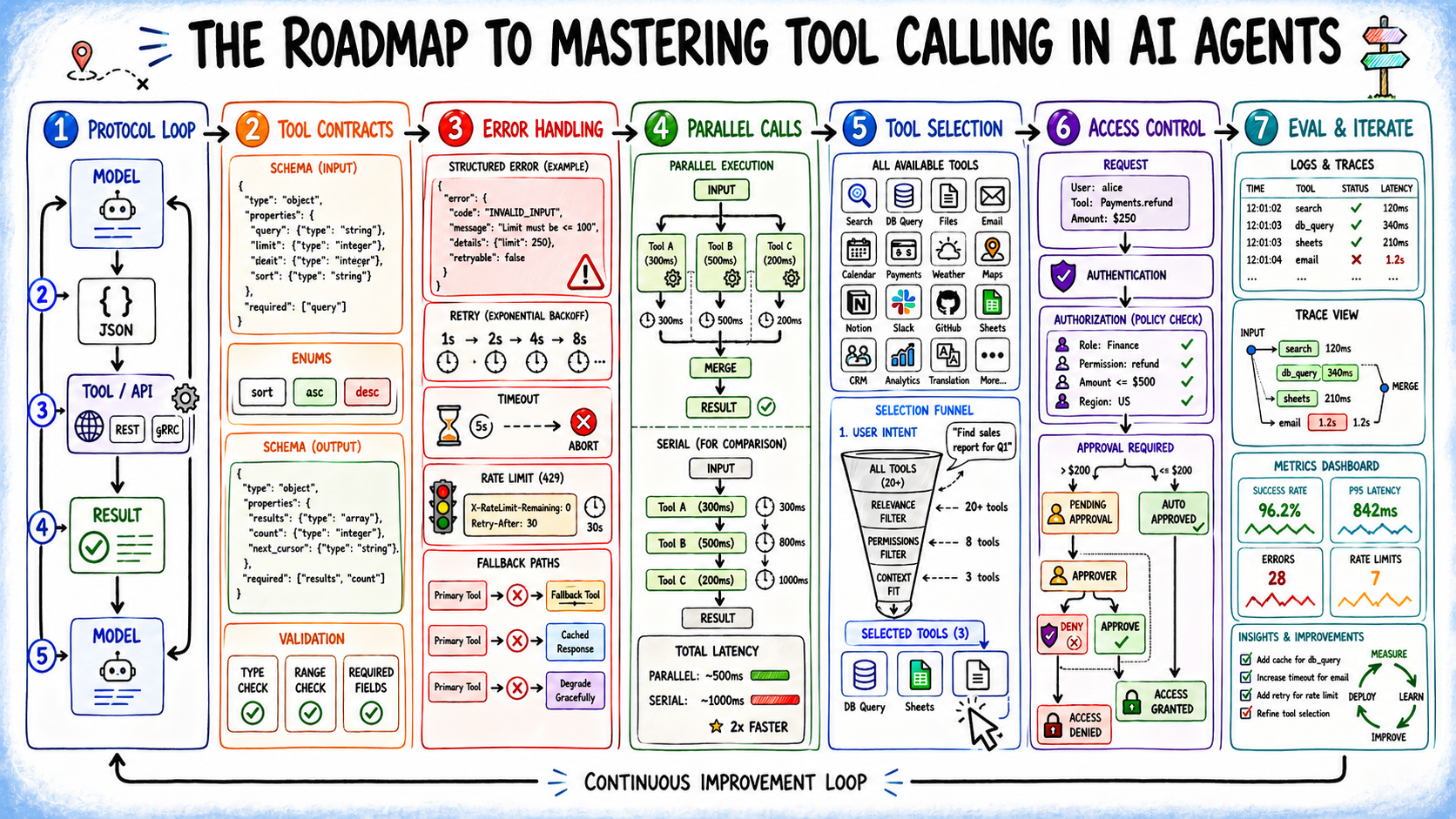
Step 1: Understanding the Tool Calling Protocol
Tool calling in AI agents works as a simple loop: the model decides what action is needed, and your system executes it.
First, you define the tools by giving the model a list with clear names, purposes, and structured input/output schemas. This sets the boundaries of what the agent can do.
When a user sends a request, the model reads it and decides whether it can answer directly or needs to use a tool. If a tool is needed, it selects the most relevant one and produces a structured JSON payload with the tool name and arguments.
- The system receives the tool call and validates the input
- It executes the actual function or API
- It handles errors and formats the result
That result is then sent back to the model, which uses it to continue reasoning and generate the final answer. More importantly, the model does not execute anything. Your application code receives the payload, validates it, runs the logic, and returns the result as new context.
The boundary matters. The model is a non-deterministic reasoner proposing actions; your code is the deterministic layer that executes and validates them. Letting the model guess at argument formats, skipping result feedback, or omitting validation blurs this contract in ways that cause silent failures at scale.
Step 2: Writing Tool Definitions as Contracts
Tool definitions are the biggest lever on whether your agent uses tools correctly. Vague descriptions produce wrong selections; loose parameter types produce bad arguments.
Strong definitions have three parts:
- A precise purpose statement including scope and conditions — “Search the web for current or time-sensitive information; do not use this for questions answerable from training data” beats “Search the web.”
- Typed and constrained parameters — prefer enums over open strings, use natural identifiers the model can infer from context, and add explicit format examples where needed.
- A clear output contract — what the tool returns, in what shape, and what partial or empty results look like, so the model reasons from signal rather than void.
Overlapping tools need explicit decision boundaries; if you have knowledge_base_search and web_search, each description must make the split obvious. Also include negative guidance; telling the model when not to call a tool prevents unnecessary invocations that add latency and burn tokens.
Step 3: Building Error Handling Into the Tool Layer
In practice, APIs rate-limit, time out, and change schemas, and OAuth tokens expire. A tool returning an empty array is worse than one returning a structured error — at least the error gives the model something to reason from.
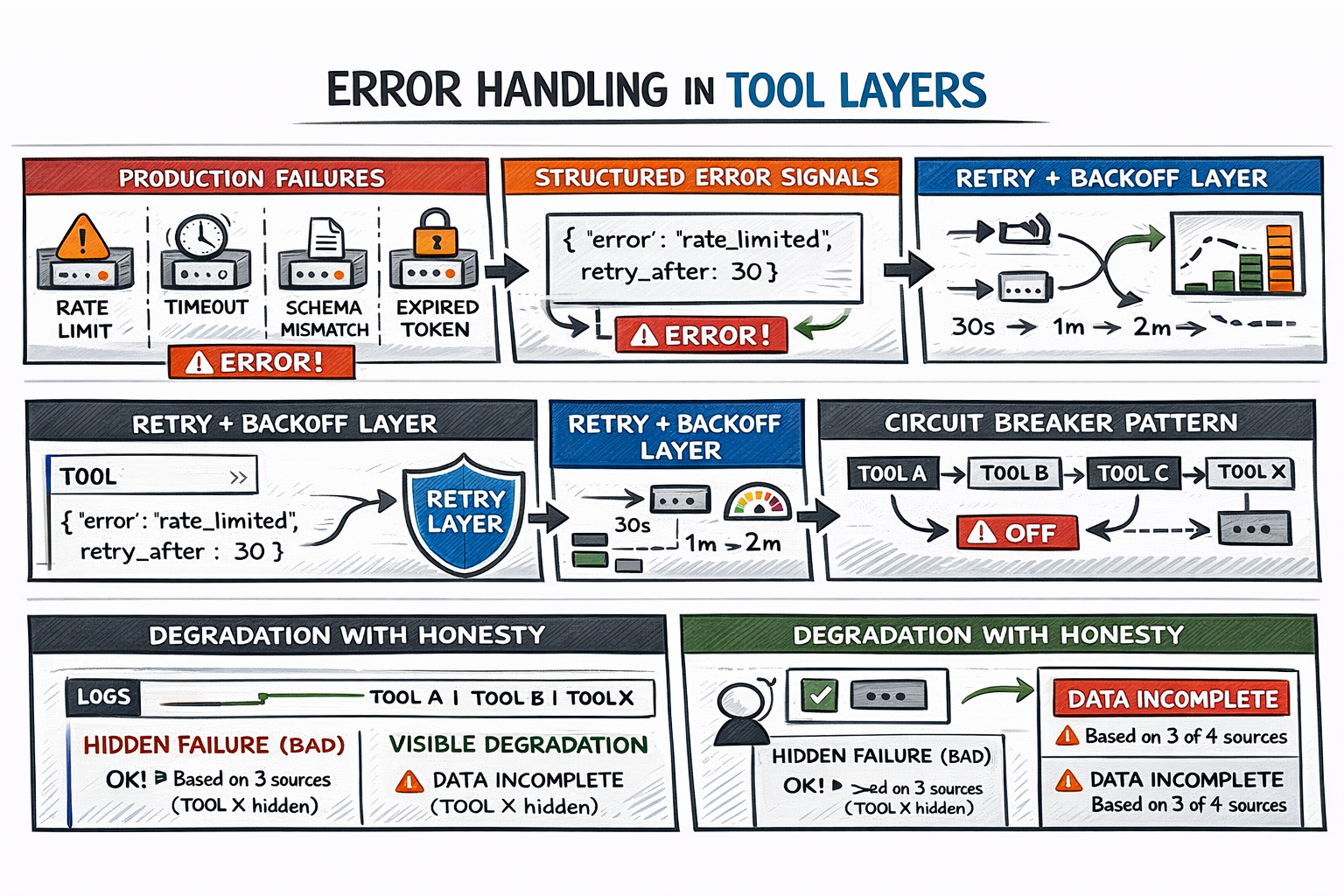
Building Error Handling Into the Tool Layer
Three practices cover the failure surface:
- Typed, interpretable error signals — an error of the form
{"error": "rate_limited", "retry_after": 30}tells the model exactly what happened and what to do next. - Transparent transient-failure handling — network blips and rate limits should be absorbed by the tool layer with exponential backoff, not surfaced raw to the reasoning loop.
- Circuit breakers for persistent failures — once a failure threshold is crossed, the tool stops being called and the model is explicitly informed it’s unavailable.
That last point is critical: the model should always know when a tool fails. An agent that answers from three out of four data sources and says so is far more useful than one that fills gaps with hallucinated content.
Step 4: Parallelizing Tool Calls Strategically
Sequential execution is the safe default, but it has a cost. When tools don’t depend on each other’s outputs, serializing them is pure latency with no benefit. So you can call tools in parallel.
The decision rule is dependency:
- If tool B needs tool A’s output as input, they’re sequential.
- If both can be called with what’s already known, they’re candidates for parallel dispatch.
Your agent orchestration framework handles the orchestration mechanics. The harder problem is infrastructure: parallel calls compete for the same rate limit headroom, connection pools, and auth tokens simultaneously — constraints invisible in sequential execution that surface all at once.
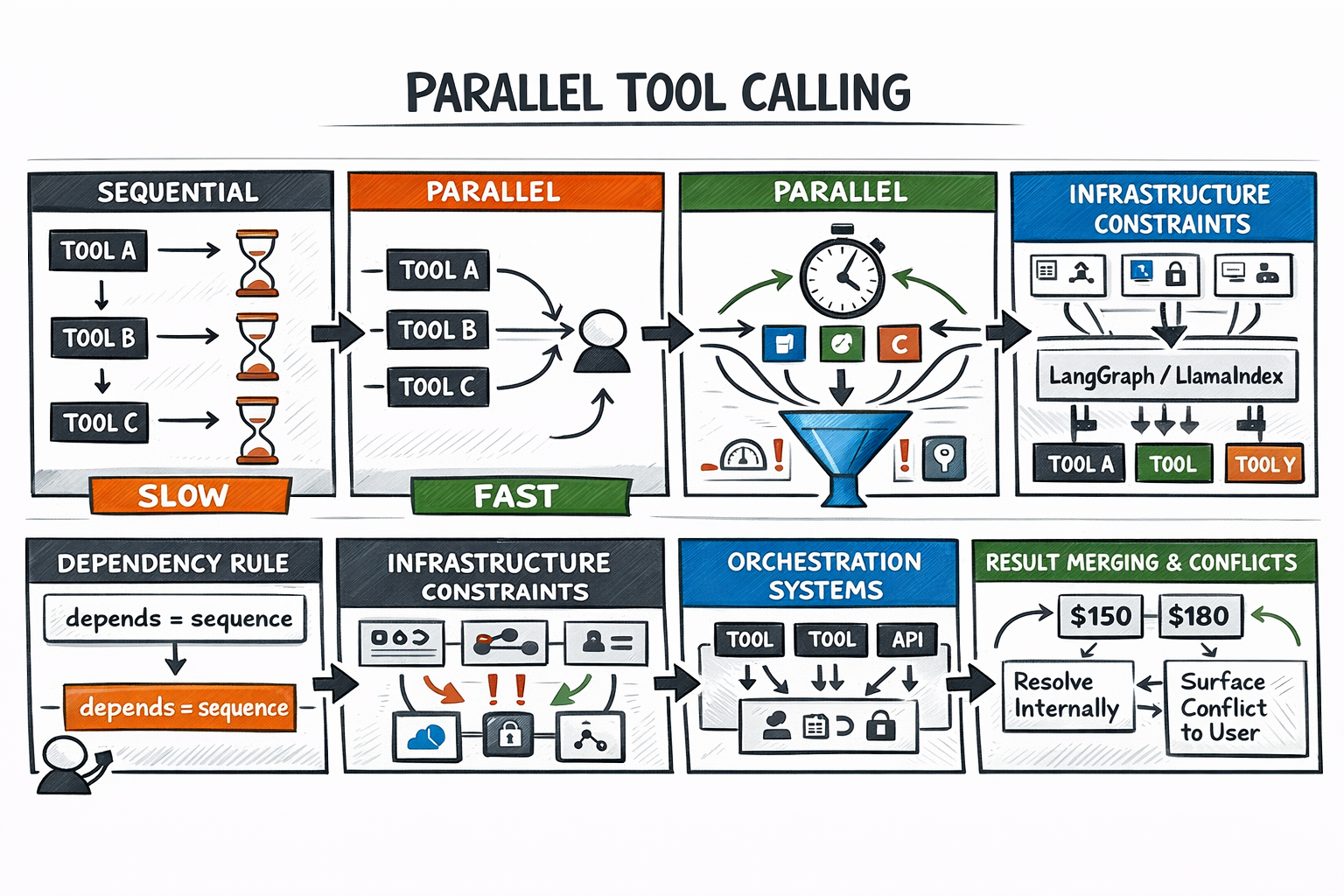
Parallelizing Agent Tool Calls
Output merging is the other failure mode. Parallel results come back independently, and the model must synthesize them. If they conflict, the model needs a defined resolution strategy — either surfacing the conflict to the user or applying a priority rule.
Step 5: Managing Tool Catalog Size
Giving agents more tools than they need degrades selection accuracy predictably. A model choosing from five clearly scoped tools substantially outperforms one scanning fifty. Large catalogs also consume input tokens that would otherwise be available for reasoning context.
The scalable solution is dynamic tool loading: retrieving a semantically relevant subset per task via vector similarity over tool descriptions, rather than registering everything upfront. Where dynamic loading isn’t practical, consistent naming prefixes group tools by domain, turning a flat search into a two-step “which category, then which tool” decision.
Audit for redundancy. Two tools that do nearly the same thing for nominally different reasons create a confusion surface every time the model chooses between them. Consolidate or differentiate; there’s no middle ground that works in production. Here’s a useful test: if you can’t articulate in one sentence why an agent would pick tool A over tool B, the boundary isn’t clear enough to ship.
Step 6: Designing for Security and Blast Radius
In production, agents trigger real transactions, send real emails, and modify real records. The blast radius of an autonomous error by tool-calling AI agents is always larger than it looked in a demo.
Two threat surfaces require deliberate design:
- Scope creep through permissions — tools should carry minimum access for their function. Read-only tools are inherently safer, and write operations with irreversible consequences should gate behind a human approval step. Pausing to surface a proposed action and require confirmation is a valid architecture choice, not a limitation.
- Prompt injection — malicious content embedded in tool outputs may attempt to redirect the agent’s subsequent behavior. Sanitizing tool results before they re-enter the reasoning context is the standard countermeasure.
The OWASP Top 10 for LLM Applications covers the full threat taxonomy for agentic systems. For any agent calling tools in production, reviewing those categories before deployment is time well spent.
Step 7: Evaluating Tool Calls and Iterating on Definitions
End-to-end task accuracy hides tool-layer problems. An agent can complete a task correctly while making inefficient tool selections, incurring unnecessary token costs, or silently recovering from earlier errors. Those patterns show up as latency, cost overruns, and reliability failures under load.
Tool-specific evaluation tracks what matters: correct tool selection rate, first-attempt argument validity, error propagation into final outputs, and recovery quality. This requires step-level traces — logs capturing each tool call, its arguments, its result, and the subsequent reasoning step. Without traces, debugging a production failure is guesswork.
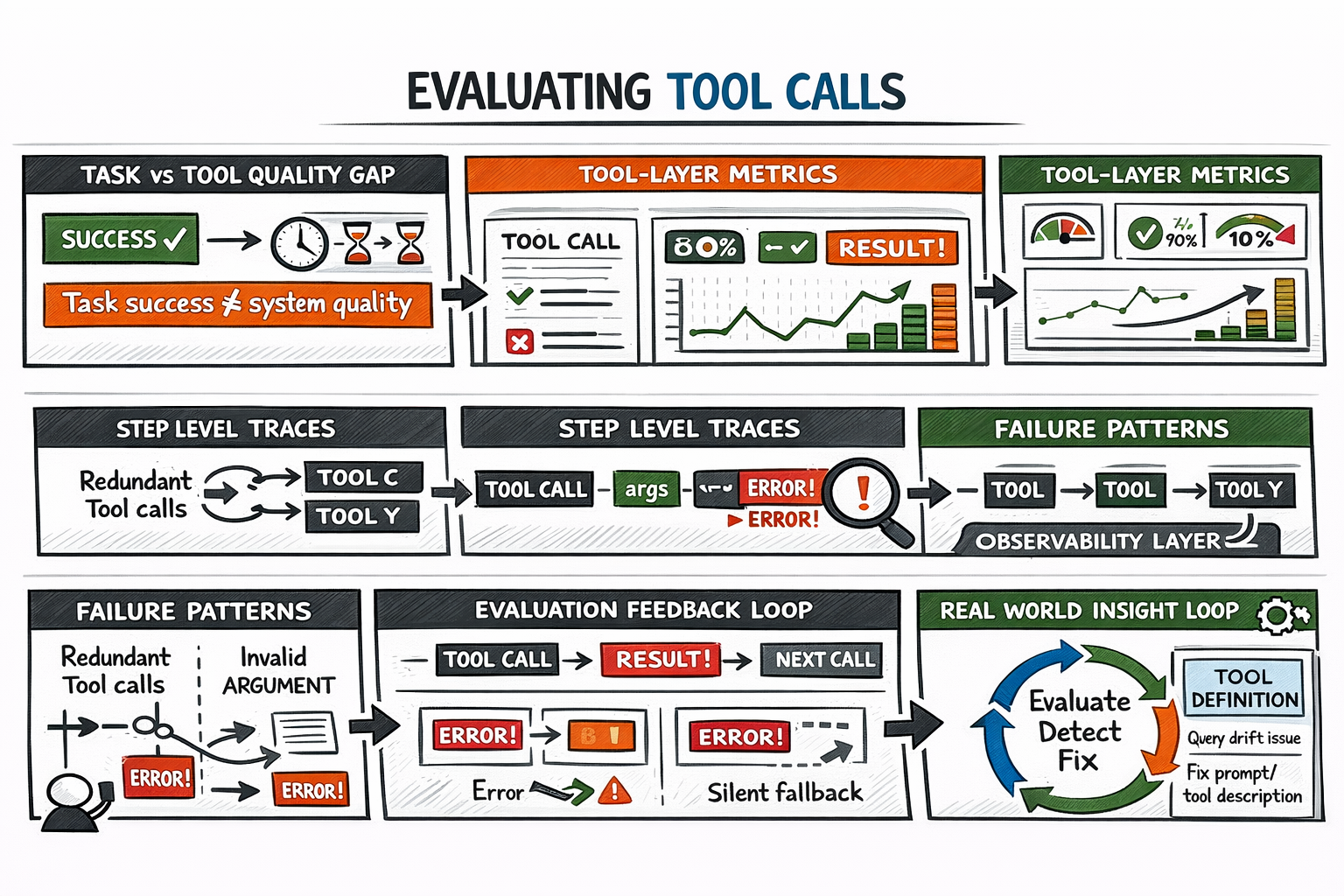
Evaluating AI Agent Tool Calls
Definitions should evolve from evaluation signals: high rates of redundant calls usually indicate scope problems; frequent invalid arguments usually indicate descriptions needing clarification or examples.
The iteration loop: build an evaluation set covering known failure modes → instrument for observability → run it → identify highest-frequency failures → update definitions or error handling → repeat.
Read How to Evaluate Tool-Calling Agents by Arize AI and Tool evaluation | Claude Cookbook to learn more.
Summary
The tool layer is where agentic systems meet the real world. Here’s a practical pattern that works: define explicit contracts, handle failures at the source, constrain scope to what’s necessary, and measure what matters before optimizing for it.
Here’s a summary of what we’ve covered:
| Step | Significance |
|---|---|
| Understanding the Tool Calling Protocol | Establishes the separation between model reasoning and execution. Prevents silent failures by enforcing validation, structured inputs, and proper feedback loops. |
| Writing Tool Definitions as Contracts | Ensures correct tool selection and argument formatting through precise descriptions, constrained inputs, and clear output schemas. Reduces ambiguity and misuse. |
| Building Error Handling Into the Tool Layer | Improves reliability by handling API failures, rate limits, and timeouts with structured errors, retries, and circuit breakers, enabling the model to respond intelligently. |
| Parallelizing Tool Calls Strategically | Reduces latency by executing independent tools concurrently while managing infrastructure constraints and ensuring proper result merging and conflict resolution. |
| Managing Tool Catalog Size | Maintains high selection accuracy by limiting tool choices, using dynamic loading, and eliminating redundancy to reduce confusion and token overhead. |
| Designing for Security and Blast Radius | Protects systems by enforcing least privilege, requiring human approval for critical actions, and mitigating prompt injection through output sanitization. |
| Evaluating Tool Calls and Iteration | Enables continuous improvement through metrics like tool accuracy, argument validity, and error handling, supported by step-level tracing and iterative refinement. |
Agent orchestration frameworks and the MCP ecosystem handle substantial infrastructure complexity, but the design decisions — what tools to expose, how to describe them, what permissions to grant, how to handle errors — require deliberate judgment that tooling can’t substitute for.





