Last Updated on April 10, 2026 by Editorial Team
Originally published on Towards AI.
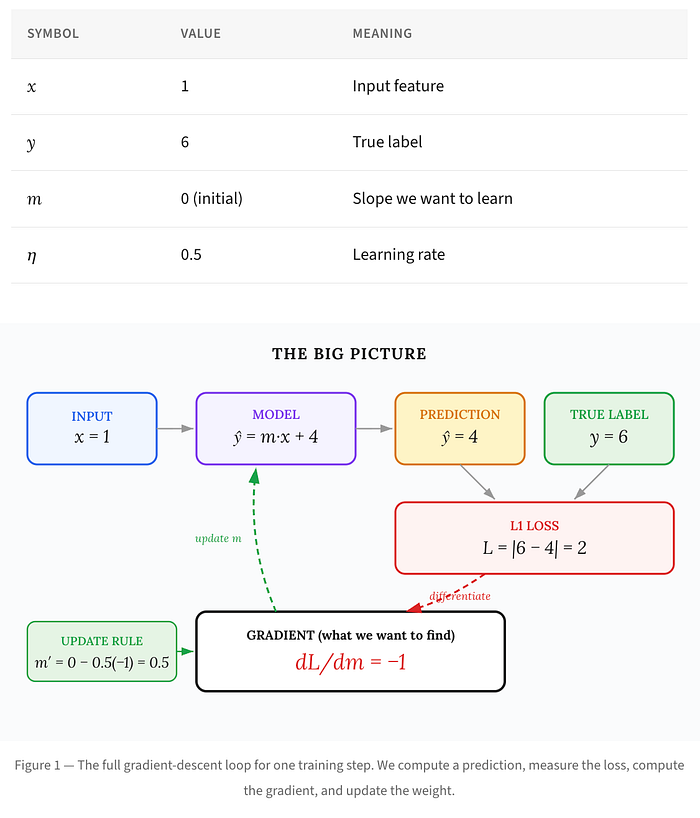
A complete, step-by-step walkthrough of how gradient descent works with absolute-value loss — with diagrams you can actually follow.
If you’ve ever read a deep learning tutorial and hit a derivative that seems to appear from nowhere, this article is for you. We’re going to break down one of the simplest — yet most instructive — gradient calculations in machine learning: the gradient of L1 (absolute-value) loss with respect to a single weight.
The article explains the gradient calculation of L1 loss through a structured approach, starting with a simple regression model and discussing its components, the loss function, and how to derive the gradient with respect to a weight. It emphasizes clarity by using concrete examples and progressively builds the understanding through the chain rule in calculus. The synopsis concludes by contrasting L1 loss’s insensitivity to outliers with L2 loss’s responsiveness to error magnitude, ultimately guiding on when to use each loss function effectively.
Read the full blog for free on Medium.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.





