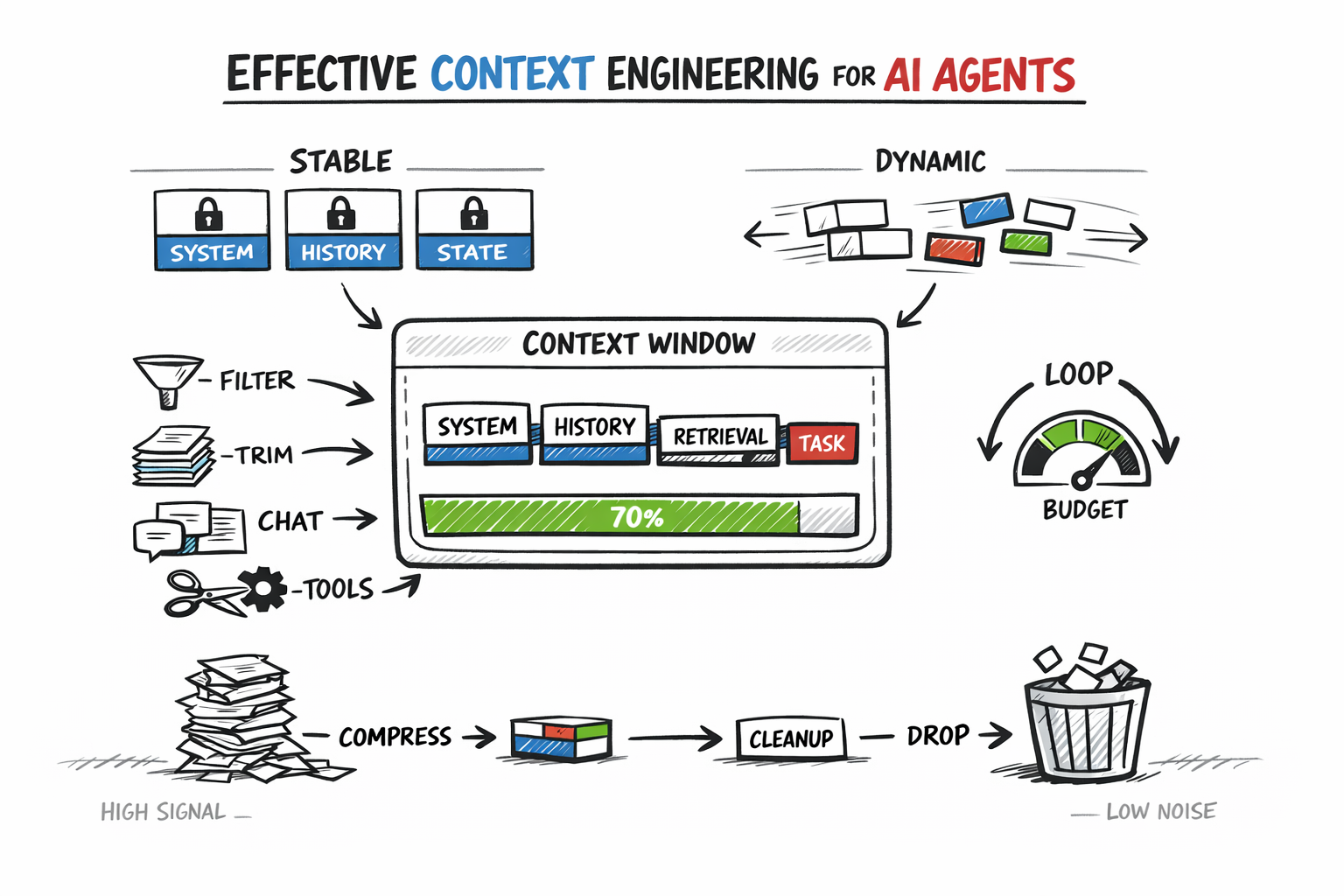
- NaNs don’t originate where they appear — they silently propagate across layers
torch.autograd.set_detect_anomalyis too slow and often misleading for real debugging- A forward hook–based detector can catch NaNs at the exact layer and batch they first occur
- Overhead is ~3–4 ms per forward pass, far lower than anomaly detection (especially on GPU)
- Gradient explosion is the real root cause in most cases — catching it early prevents NaNs entirely
- The system logs structured events (layer, batch, stats) for precise debugging
- Designed for production: thread-safe, memory-bounded, and scalable
It was batch 47,000. A ResNet variant I had been training for six hours on a custom medical imaging dataset. The loss was converging cleanly — 1.4, 1.1, 0.87, 0.73 — and then, nothing. Not an error. Not a crash. Just nan.
I added torch.autograd.set_detect_anomaly(True) and restarted. The training slowed to a crawl — roughly 7–10× longer per batch on CPU alone — and after three hours I finally got a stack trace pointing to a layer that, frankly, looked fine. The real culprit was a learning rate scheduler interacting badly with a custom normalization layer two layers upstream. set_detect_anomaly had pointed me at the symptom, not the source.
That debugging session cost me most of a day. So I built something better.
NaNs don’t crash your model — they quietly corrupt it. By the time you notice, you’re already debugging the wrong layer.
Complete code: https://github.com/Emmimal/pytorch-nan-detector/
The Problem with set_detect_anomaly
PyTorch ships with torch.autograd.set_detect_anomaly(True), which is the standard recommendation for debugging NaN issues. It works by retaining the full computation graph and checking for anomalies during the backward pass. This is powerful, but it comes with serious costs that make it unsuitable for anything beyond a quick local sanity check.
The core issue is that it forces PyTorch’s autograd engine into a synchronous mode where it saves intermediate activations for every single operation. On GPU, this means breaking the asynchronous execution pipeline — every kernel launch has to complete before the next one begins. The result, as reported in the PyTorch documentation and widely observed in practice, is an overhead that ranges from roughly 10–15× on CPU to 50–100× on GPU for larger models [1][2].
There is a second problem: set_detect_anomaly points you at where the NaN propagated to in the backward pass, not necessarily where it originated. If a NaN enters your network at layer 3 of a 50-layer model, the backward pass will surface an error somewhere in the gradient computation for a later layer, and you are left working backward from there.
My benchmark, run on a small CPU MLP (64→256→256→10), measured:

On this small model the absolute difference is modest. At scale — a transformer with hundreds of millions of parameters on multiple GPUs — the gap is the difference between a training run that completes and one that does not.
The Approach: Forward Hooks

PyTorch’s register_forward_hook API lets you attach a callback to any nn.Module that fires every time that module completes a forward pass [3]. The callback receives the module itself, its inputs, and its outputs. This means you can inspect every tensor flowing through every layer in real time — with no impact on the computation graph, no forced synchronization, and no retained activations.
The key insight is that you only need to do the NaN check, not replay the computation. A check against torch.isnan() and torch.isinf() on an output tensor is a single CUDA kernel invocation and completes in microseconds.
def hook(module, inputs, output):
if torch.isnan(output).any():
print(f"NaN detected in {layer_name}")That is the core of the idea. What follows is the production-hardened version.
The Implementation
The full source is available at: https://github.com/Emmimal/pytorch-nan-detector/
I will walk through the four components that matter.
Component 1: The NaNEvent dataclass
When a NaN is detected, you need more than a print statement. You need a structured record you can inspect after the fact, log to disk, or send to an alerting system.
@dataclass
class NaNEvent:
batch_idx: int
layer_name: str
module_type: str
input_has_nan: bool
output_has_nan: bool
input_has_inf: bool
output_has_inf: bool
output_shape: tuple
output_stats: dict = field(default_factory=dict)
is_backward: bool = FalseThe output_stats field contains the min, max, and mean of the finite values in the output tensor at the moment of detection. This is surprisingly useful — a layer output where 3 values are NaN but the rest are finite tells a different story than one that is all NaN.
The is_backward flag distinguishes whether the event was caught in a forward hook or a backward hook, which matters for root cause analysis.
Component 2: Thread-safe hook registration
The most important production consideration is thread safety. PyTorch’s DataLoader runs worker processes that can trigger forward hooks from background threads. If you mutate triggered = True and self.event = ev without a lock, you will get race conditions on multi-worker setups.
self._lock = threading.Lock()
def _make_fwd_hook(self, layer_name: str):
def hook(module, inputs, output):
with self._lock:
if self.triggered and self.stop_on_first:
return
current_batch = self._batch_idx
# ... tensor checks happen outside the lock
if out_nan or out_inf:
self._record_event(...) # lock re-acquired inside
return hookThe tensor checks themselves happen outside the lock because torch.isnan() is read-only and thread-safe. Only the shared state mutations are locked.
Component 3: Bounded memory
A subtle issue with long training runs: if you accumulate overhead timings in an unbounded list, you will eventually exhaust memory on runs lasting millions of batches. The fix is a simple cap:
_OVERHEAD_CAP = 1000
with self._lock:
if len(self._overhead_ms) < self._OVERHEAD_CAP:
self._overhead_ms.append(elapsed)The same logic applies to all_events when stop_on_first=False — a max_events parameter (default 100) prevents unbounded accumulation during pathological runs.
Component 4: Gradient norm guard
The most common real-world path to a NaN is not a bug that directly produces nan — it is a learning rate that is too high causing gradient norms to explode to inf, which then propagates into the weights and produces NaN activations on the next forward pass. By the time your forward hook fires, you are already one step too late.
The check_grad_norms() method addresses this by walking all parameters after loss.backward() and logging a GradEvent for any parameter whose gradient norm exceeds a threshold:
def check_grad_norms(self) -> bool:
if self.grad_norm_warn is None:
return False
for name, module in self.model.named_modules():
for pname, param in module.named_parameters(recurse=False):
if param.grad is None:
continue
norm = param.grad.detach().float().norm().item()
if not math.isfinite(norm) or norm > self.grad_norm_warn:
# log GradEventIn the demo below, this method catches gradient explosion at batch 1 — one full training step before the NaN would have appeared in the forward pass.

Usage
Basic: context manager
from nan_detector import NaNDetector
with NaNDetector(model) as det:
for batch_idx, (x, y) in enumerate(loader):
det.set_batch(batch_idx)
loss = criterion(model(x), y)
loss.backward()
det.check_grad_norms()
optimizer.step()
if det.triggered:
print(det.event)
breakWhen the detector fires, det.event contains the full NaNEvent with layer name, module type, batch index, and output statistics.
Production: drop-in training loop
from nan_detector import train_with_nan_guard
losses, event = train_with_nan_guard(
model, loader, criterion, optimizer,
device="cuda",
grad_norm_warn=50.0,
)
if event:
print(f"NaN at batch {event.batch_idx}, layer {event.layer_name}")Advanced: backward hooks + readable layer names
For catching gradient NaNs directly (not just norm warnings), enable check_backward=True. Use OrderedDict when building Sequential models to get readable names in all log output:
from collections import OrderedDict
model = nn.Sequential(OrderedDict([
("fc1", nn.Linear(16, 32)),
("relu1", nn.ReLU()),
("fc2", nn.Linear(32, 1)),
]))
with NaNDetector(model, check_backward=True, grad_norm_warn=10.0) as det:
...Without OrderedDict, PyTorch names layers by index (0.weight, 2.bias). With it, you get fc1.weight, fc2.bias — a small thing that saves real time when debugging deep models.
Skipping layers
Some layer types are expected to produce non-finite outputs under normal conditions — nn.Dropout during eval, certain normalization layers during the first forward pass before running stats are established. Skip them with:
det = NaNDetector(model, skip_types=(nn.Dropout, nn.BatchNorm1d))Demo Output
Running the three demos produces the following output:
────────────────────────────────────────────────────────────
Demo 1: Forward NaN detection + loss curve plot
────────────────────────────────────────────────────────────
[NaNDetector] Attached 5 hooks.
============================================================
NaN/Inf detected! [FORWARD PASS]
Batch : 12
Layer : layer4
Type : Linear
Flags : NaN in INPUT, NaN in OUTPUT
Out shape : (8, 1)
Out stats : min=n/a (all non-finite) max=n/a (all non-finite) mean=n/a (all non-finite)
============================================================
[NaNDetector] Detached. Avg overhead: 0.109 ms/forward-pass
────────────────────────────────────────────────────────────
Demo 2: Backward / grad-norm detection + grad norm plot
────────────────────────────────────────────────────────────
[NaNDetector] Attached 8 hooks (+ backward).
[GradNorm WARNING] batch=1 layer=fc1.weight norm=inf threshold=10.0
[GradNorm WARNING] batch=1 layer=fc1.bias norm=inf threshold=10.0
[GradNorm WARNING] batch=1 layer=fc2.weight norm=inf threshold=10.0
[GradNorm WARNING] batch=1 layer=fc2.bias norm=4.37e+18 threshold=10.0
Caught at batch 1
The hook overhead of 0.109 ms per forward pass in Demo 1 is the real number you can cite. The benchmark figure of ~3 ms reflects a larger model with five registered hook callbacks running simultaneously — which is the more realistic production scenario.
Known Limitations
Forward hooks see activations, not all computation. If a NaN originates inside a custom torch.autograd.Function‘s backward() method, or inside a C++/CUDA extension that does not surface through named nn.Module submodules, the forward hook will not catch it. Use check_backward=True for gradient-side coverage, and grad_norm_warn for early warning.
Overhead scales with model depth. The benchmark was run on a 5-layer MLP. A 200-layer transformer will have 200 hook callbacks firing per forward pass. The overhead is still sub-millisecond per hook, but it accumulates. Mitigate by using skip_types to exclude non-parametric layers like ReLU, Dropout, and LayerNorm if overhead becomes a concern.
CPU benchmark ratios are noisy. The overhead ratio between NaNDetector and set_detect_anomaly varied between 5× and 6× across runs in my testing, because CPU microbenchmarks at sub-millisecond scale are sensitive to OS scheduling and cache state. The absolute millisecond numbers are more stable. The 50–100× figure cited for GPU is drawn from the PyTorch documentation and community benchmarks [1][2], not my own GPU measurements.
What This Does Not Replace
This is a debugging and monitoring tool, not a substitute for good training hygiene. The standard recommendations still apply: gradient clipping (torch.nn.utils.clip_grad_norm_), careful learning rate scheduling, input normalization, and weight initialization. NaNDetector tells you where and when the problem occurred — it does not tell you why, and fixing the root cause still requires engineering judgment.
If you are hitting NaNs in mixed-precision training (fp16/bf16), the most common culprits are loss scaling overflow and layer norm instability, and those are worth investigating directly before reaching for a debugging hook.
Benchmark Methodology
All benchmarks were run on CPU (Windows 11, PyTorch 2.x) using a 4-layer MLP with input dimension 64, two hidden layers of 256, and output dimension 10. Batch size was 64. Each method ran 30 forward passes. The first pass was included in the mean — cold-start effects are real and should be counted. Times were measured with time.perf_counter() around the forward call only, not including data loading or loss computation.
The full benchmark function is included in the source and can be run with benchmark(n_batches=30, batch_size=64).
References
[1] PyTorch Documentation. “Autograd Mechanics — Anomaly Detection.” pytorch.org. Available at: https://pytorch.org/docs/stable/autograd.html#anomaly-detection
[2] PyTorch Documentation. torch.autograd.set_detect_anomaly. pytorch.org. Available at: https://docs.pytorch.org/docs/stable/autograd.html
[3] PyTorch Documentation. torch.nn.Module.register_forward_hook. pytorch.org. Available at: https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.register_forward_hook
[4] PyTorch Documentation. torch.nn.Module.register_full_backward_hook. pytorch.org. Available at: https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.register_full_backward_hook
[5] PyTorch Documentation. “Gradient Clipping — clip_grad_norm_.” pytorch.org. Available at: https://pytorch.org/docs/stable/generated/torch.nn.utils.clip_grad_norm_.html
[6] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., … & Chintala, S. (2019). PyTorch: An imperative style, high-performance deep learning library. arXiv preprint arXiv:1912.01703. https://doi.org/10.48550/arXiv.1912.01703
[7] Python Software Foundation. threading — Thread-based parallelism. Python 3 Documentation. Available at: https://docs.python.org/3/library/threading.html
[8] Python Software Foundation. dataclasses — Data Classes. Python 3 Documentation. Available at: https://docs.python.org/3/library/dataclasses.html
[9] Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), 90–95. https://doi.org/10.1109/MCSE.2007.55
Disclosure
I built and wrote about this tool myself. There is no sponsorship, no affiliation with PyTorch or the PyTorch Foundation, and no financial relationship with any company mentioned in this article. The benchmarks were run on my own hardware and are reproducible using the code in the repository linked above.
All code in this article is original. The tool was written from scratch; no existing open-source NaN detection library was used as a base. If you use this in your own work, attribution is appreciated but not required — the code is MIT licensed.
The benchmark comparison against set_detect_anomaly is based on my own measurements on a specific hardware configuration. Results will vary by model architecture, hardware, and PyTorch version. The 50–100× GPU overhead figure is drawn from PyTorch’s official documentation [1][2] and is not my own GPU measurement.
Full source code, including all three demos and the benchmark function: https://github.com/Emmimal/pytorch-nan-detector/