Transcript
Adam Wolff: I'm Adam Wolff. I'm an engineer on the Claude Code team. Today I want to talk, not about Claude Code and how to use it, but instead about how we build Claude Code using Claude Code. This is a case study of what happens if you give a team Claude Code and you orient your project around it. When I told Faye what I wanted to talk about, I told her I'm going to talk about how simple Claude Code is and how that enables us to move fast. Then I started doing some spelunking in our repository. You'll see, these stories are anything but simple. They're actually quite complicated. Even the simple things end up being complicated by the time we ship them.
The point is not necessarily about what's simple or complex. It's about the way that AI has changed the bottlenecks in the Software Development Life Cycle, where implementation used to be the big piece. You would have to spend a lot of time up front figuring out what you're trying to build and how you're going to build it. Now it's usually better to charge ahead and let your users and your development process tell you what to build. I'm going to tell a few stories and trace through how some modules in Claude Code evolved.
The last story is about shipping something and removing it in like two weeks, something that I've never seen before. I'm excited to share some of these stories with you. Any Claude Code users here? If you haven't tried it, I highly recommend it. I'm proud of it. I think it's a great product. Claude Code is one of the heaviest users of Claude Code. We calculate that 90% of the code that we ship to production is written by or with Claude. We also ship continuously internally. We have a very engaged user base within Anthropic. We try to ship daily, on weekdays, externally. Very fast releases, very robust feedback channels. The users really depend on this tool. We hear from them when we break something or when they have a feature request.
Scope (Three Stories)
Today I'm going to share three stories from the development of Claude Code. They each evolved differently. I think they show how AI doesn't solve these problems that we have as software developers. Everything ends up being pretty complicated at the end. It does change the way we should think about these problems and where some of the bottlenecks that we're trying to speed up are. In each one of these stories, let's keep an eye on the following things. Why did we have to ship to find out the real requirements? What architecture choices really mattered in the end? How did we know when we had to press through the pain versus turn around? Because everything you do is going to have some pain involved. The question is, when is that pain too much? How does it tell you you're going in the wrong direction?
Episode I - Rebuilding Input
To start off, I'm going to tell the story about the cursor class in Claude Code. I chose a picture of a slide rule here, one, because I could find ASCII clip art for it, but two, because the slide rule is where we get the word cursor. The part that moves on the slide rule was originally called the cursor. That's how we ended up with that name for the blinking thing where your text goes in a computer program. Here's the problem from our point of view. We're going to run Claude. We know from the get-go that we want to have all these special behaviors when you type special characters in Claude. You can see, I can go into this fancy menu by typing a slash command. I can also @ mention a file name. We're going to have to look on your disk.
Then I want to be able to tab complete that. There's a lot we want to do when we take your input. We know that we're going to need to intercept each keystroke to get these behaviors. Unfortunately, these behaviors are quite complicated. There's a lot of them. The conventional wisdom is you do not want to rebuild input. If you've used React and you've used a controlled component for text input, you know some of the perils that you end up with here. There's a lot of behaviors that users expect that are not built in. I'll just show you, I have this really short program where I'm going to use Readline, which is like the old C library for taking user input. It goes back to Emacs days and the very beginnings of Linux. Let's run this program now. I can type, obviously, into here. There are a lot of other behaviors. I can hit Ctrl-A, that takes me to the beginning. Ctrl-E takes me to the end. If I go here and Ctrl-K and kill, I can do Ctrl-Y and paste that back. Ctrl-H, that's a classic. I can say, obviously, dogs. I can keep going here. There's a lot of functionality. What are we going to do about this when we totally replace the input with something that is under our control? It doesn't seem like a real choice here. We know we want to have these behaviors. We know that this program is mostly going to be about taking input from the user. We need this control. We go ahead and build this virtual cursor class.
To do this, we need to do our own wrapping. Word wrapping, if you've ever done it, is hard. You need to backtrack to have a proper word wrapping algorithm. You can't tell just by looking at the next character whether you're going to wrap or not. It's a tricky implementation. We build this cursor class. It's like 300 lines. The most important thing about it is that it's fully testable. We can render it in a way that we can make an assertion about how the cursor appears in the string. It's also immutable inside. It's got this fluent interface. The way it works is you operate on the cursor, and you get a new cursor. That obviously helps with concurrency and makes it more testable. This is one of my first contributions to Claude Code. I was pretty happy with it. It fixed some bugs with wrapping and its input. Very clean API. Super nice test coverage. There were bugs at first, but we worked them out, and thought, this thing is pretty good.
Then, I felt sure we were on the right track when two months later, we were going to ship externally. Right as part of the first release, my friend on the team implemented Vim mode. I'm a diehard Vim user. I just thought this was awesome because this is something you really can't do easily if you use something like Readline. The tests are what really made this possible. You can see here how this testability was easily extensible to Vim mode. This all shipped in one PR. It wasn't simple. It was maybe an additional amount of code that was bigger than the original implementation, covered by a gazillion tests. It wasn't that hard. If you've used Claude Code, you know the AI really helps with this kind of development, especially when it can run the tests and then tweak the implementation. It goes pretty fast. This was a case of our architectural choices really paying off.
Two months later, we're starting to see international adoption. This is where we learn why everyone tells you not to rebuild input, or one reason not to rebuild input. I can answer that succinctly now. I can tell you Unicode is the reason not to rebuild input. This is one tricky case where we have these special characters that are double wide, A B C, the second row here. It turns out that in Unicode, there's an arbitrary mapping between the number of code points you have, the number of characters you have, and the number of columns you have. All of those things can vary arbitrarily in Unicode.
The first thing we need to add here is grapheme clustering. Instead of just breaking on character boundaries, we need to use grapheme clusters and identify those as the word boundaries. We introduce it. Again, we have comprehensive tests. This goes in pretty quickly. It's complicated, but it's not so bad. We ship this, and now we're starting to work with the international users. We're starting to use it more. We get this bug report that when I hit the End key, the cursor doesn't actually go to the end of the line.
This turns out to be another issue with Unicode. Now we have two forms where we can represent the same string in different ways. This is another example of Unicode being tricky. You can have a Unicode code point that is just the accent. It combines with the previous thing. What do we need to do? We need to normalize the whole cursor class to all be NFC, one representation everywhere. This is a major refactor. We move a bunch of functionality inside this new class that we developed. We hide details of the interface. We add a bunch of consistency stuff. Again, it's really not that bad. It's another refactor. It's another few hundred lines of code, a lot more tests. Claude Code is a superstar here. This is just what it does so well.
This goes on for a while. Claude Code starts doing more and more stuff in the background. Typing is slowing down more and more. This is another reason why people are wary of taking input, because we're running a bunch of JavaScript every time the user presses a key. We're a long way from the cursor blinking in sync with the hardware, which is where the terminal started. We go back and look at this code that we've written. We're like, this is not very optimized. Basically, we're eagerly doing all this computation, no matter what is happening. If you hit the left key, we don't need to relay out all of the text, but we do. Optimization pass. Again, my same friend who implemented Vim mode went back and did this optimization pass. He said, "I got nerd sniped hard", which I just love.
Basically, in a day or so, totally and thoroughly optimizes this class. Again, now using a benchmark in addition to the test, it goes really fast. We get it much faster. I'll just show you what this code looks like. Claude helped me. I wrote a very simple demonstration here where you can see eager cursor always wraps in the constructor. Lazy cursor doesn't do anything in the constructor. When you render, you check what you might need to do to layout. Now I can show this silly little demo. I can show you, obviously, by deferring work, that's one of the few true optimizations you can make, is doing less work. It works here. We get it nice and fast. This is a story that I'm going to call a huge win. We did something you're not supposed to do. We re-implemented input. We shipped a bunch of bugs but we fixed them fast. We now have this total control over input. It went super well. The next question is like, ok, that's a great win for you guys, I'm happy for you, what does it look like when this doesn't go quite as well? The next two stories are all about that.
/filters:no_upscale()/sponsorship/eventsnotice/2c3c9704-98d2-4d27-8bcc-70bf2fc91d2a/resources/1YugabyteWebinarMay12-transcripts-1774546444287.png)
Episode II - Reimagining Shell
This next one is about Claude's shell. If you've used Claude, you know that Claude uses, we call it the Bash tool. It can actually be Bash or Zsh, because so many people use Zsh. This next story is about how we went about implementing this. It's a sunny day. I wake up. It's like, time to do some work on Claude's shell. How hard can it be? You just need to send a command to Bash and then have it process it and get the result. Turns out very hard. I'll just walk you through some of these complications that we faced.
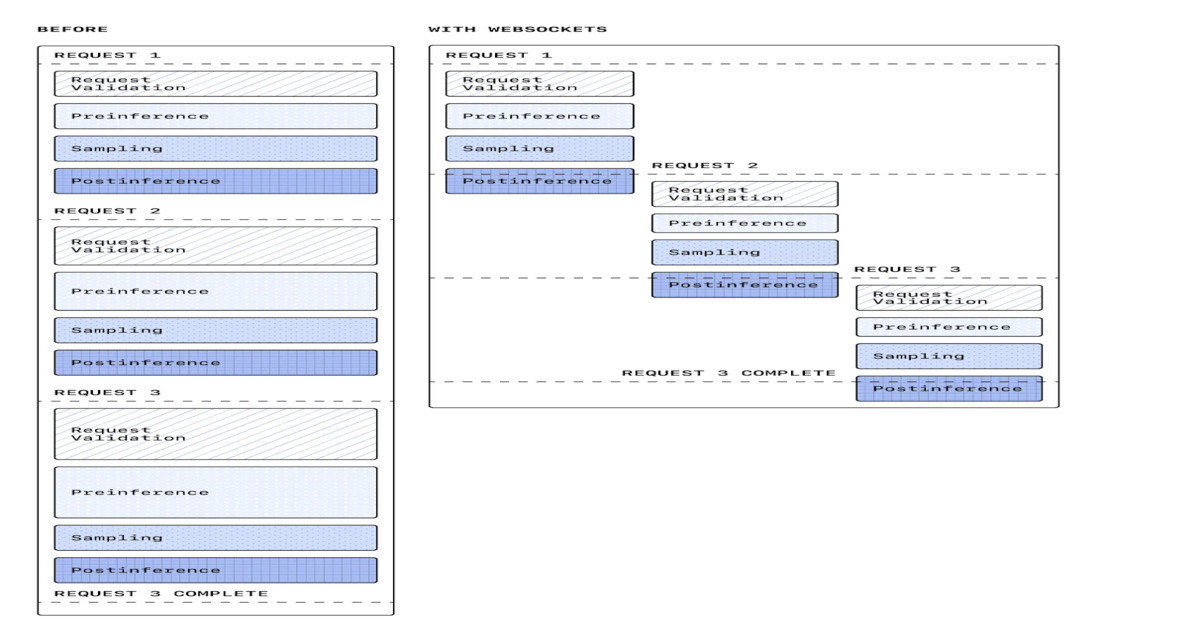
First, let me give a little demo of where we ended up. This is how Claude works now. If I tell Claude like, run a few Bash commands, see what's going on in this repository, Bash is really the way it relates to the world. You'll see it'll think for a little bit, and now it just runs like 8 zillion Bash commands. You'll also note that they all kind of run at the same time. That's actually really important, and I'll come back to that. That's not where we started. Where we started was a class I literally called persistent shell. It was the most naive possible implementation of this abstraction. I'm typing into a terminal. I type commands, I get the response. I want Claude to conceptually do the same thing. I give Claude a persistent shell. It can run one command at a time. We will wait for the output of that command and then process the next one. It turns out that actually getting this concurrency right and guaranteeing this kind of sequential operation and recovering from faults is quite difficult. That turned out to be pretty complicated, but it was doable. One of the benefits here is that the environment persists.
If Claude changes directory, of course, you've changed directory in the shell. What else is going to happen? If Claude exports a new value for an environment variable, that will stay there. It has problems. Those are obvious when we start building this thing called batch tool, which allows us to execute tools in parallel. This has turned out to be very important for agent performance. We didn't really know this going in. Persistent shell is now the bottleneck. Even if the batch tool can execute commands concurrently, persistent shell will make them all serial and slow us down.
We know we have to pivot. What are we going to do? The obvious answer is like, somehow, we have to take this persistent shell and make it more transient. We delete the original implementation of persistent shell. It's a lot of code that I've laboriously crafted, but we'll get rid of it. We replace it with just something I called shell. I referred to it as transient shell at the time. The result is like, wow, it's a lot faster. I don't have to belabor this point. Anyone who's ever programmed a computer knows doing things in parallel is faster than doing them sequentially. Again, this is another one of these optimizations that like, this actually makes a difference. It's very important. What are we going to do? It's not obvious how to get output out of a shell. We need to support a lot of things here. Claude can write a bad bash command. It can write a command that opens a quote and never closes it. We don't want to crash just because Claude sent us a bad shell command. We also want to make sure we don't corrupt the shell.
Then, also, Node makes this much harder. I hate to say this, because I love Node and I love TypeScript. Python is a little better for these kinds of things. When you use things like pipes and file descriptors, it's much closer to the real syscalls. Node emulates a lot of this stuff. Let me just give a quick example of that. Two problems here. One is that you can tell Node to spawn within a shell, which is fine, but it's a lot slower. We already said, we're trying to speed things up. This makes it like two times as slow to spawn with a shell. The other thing is like, in C or in Python, I can create a pipe and then hook it up later, which is really valuable with these kinds of concurrency and especially error recovery. Can't do that in Node. You have to have your pipe ready and hook it up before you spawn, which really constrains the implementation. We tried a gazillion different ways of doing this. We tried writing to stdout. We tried talking to it over stdin. We tried pulling file descriptors. There's a lot of ways to do this.
In the end, we found something that works and we implemented it. In the spirit of Claude Code, I just shipped it internally. It was missing a really important feature. It was missing the user's environment. Because we're spawning here, we're not getting all of your bash_profile, bashrc, or zshrc, or whatever. We also had to re-implement working directory tracking, which is, again, tricky. You have to see where you ended up at the end of the spawn command and record that in the program. Getting this wrong really confuses Claude, it really confuses the users as well. Also, we lost this environment variable persistence, important behavior change. This didn't work at all. I turned it on for maybe a day. People were like, you can't do this. It turns out that the way people customize their shell is a non-negotiable part of their user environment. Claude needs to be able to run all your aliases. It needs to inherit all your environment variables. Or, basically, it doesn't work with your project. This is one of these things where, like, you discover the requirements by poking at them. We poked and got poked back.
We need to figure out, how do we recover the user's environment for these transient shells? Again, not obvious. This is a moment when it's like, maybe we're on the wrong path here. Do we definitely want to do this, make up some way of capturing the user's environment? I think we made the right choice here. The reason why is because we'd already felt the benefits of the architecture. We saw that we were faster. We saw that the implementation was simpler when we got rid of this queue. Our bet was that this is worth it. It was not easy.
We come up with this idea of a snapshot. What we're going to do is we're going to start the user's environment once and then try to capture it. Then we will replay a script that creates that environment every time we spawn a command. Hopefully, it'll be nice and fast. There's a lot of rough edges here. If you've ever worked with shells and bash and Zsh, bash is 60 or 70 years old now? It's got a lot of hairs on it. It's pretty quirky that you can have special characters and aliases. You can have aliases that refer to functions, that refer back to aliases. There's an order where you have to dump out this environment to get it to come out correctly. There's all kinds of error conditions where if you have a problem while you're trying to capture this environment, you sure as heck don't want to capture the problems. This was like, what are we talking about here? A seven-month journey of finding out real problems caused by real users using their real shells.
Again, very hard to discover at a requirements phase. Just going to walk you through some of this real pain that I live through. People have very funky shell configs where you make a choice at the beginning, and then it loads different versions of their shell. They alias something so that you always get asked when you try to remove something. This is a real problem for Claude. It can't really deal with this kind of interactive stuff yet. There are edge cases everywhere. You can have funky Heredoc stuff. You can have functions, again, that rely on input. The differences between Bash and Zsh are enough to make this hairy. This is where we ended up. We ended up with a snapshot implementation. The way it works is like, we're going to declare a temp file. We are going to start the user shell. Then once we have that thing running, we're going to dump the aliases and declare the functions. We'll do this all in the right order. It took three weeks to come up with exactly how this was going to work, of iterating, trying stuff with our users internally. These snapshots were hard.
The interesting thing is at the end of the day, all the smoke clears, dust settles, it was still simpler than persistent shell. We did make the right architecture choice. A big part of the reason here is that snapshots are composable with this transient shell. The nice thing about it is that, yes, there's a bunch of complexity in the snapshot, but it's all in its own file. I think we all know that modular complexity is much better than tangled hairball complexity. We're looking for more evidence that this was the right design. It came when we wanted to do sandboxing. There's a lot of reasons why you don't want to trust Claude to run any old command. You also want to try to avoid permission prompts if you can. We developed a snapshot abstraction. The nice thing about this transient shell is that it plugs in really well. You can always wrap a command using another command. argv is the original form of Linux composability or Unix philosophy. You can do this LD_PRELOAD thing on Linux. I don't want to say that sandbox was simple or easy. It wasn't. It's like 3,000 lines of really hairy stuff, but the integration with shell was simple. It goes in really nicely.
This is a case where we had to make tradeoffs. Our original requirements were that we had to have a persistent shell. We realized that that actually puts us in too much of a box. We need to emulate a persistent shell, but we don't really want to use that abstraction. In this case, I think the speed that we gained, both for the user in terms of parallelism and for the developer in terms of composability, were worth it. I also want to say, look, the first story about cursor was all about tests. There are times when tests are a godsend. They're exactly what you need to move fast. Not in this case. Persistent shell had a ton of tests. We just had to delete them because the abstraction was wrong. It's not as simple as just write tests. It never is, unfortunately. This is the architecture that emerged. You can see, it's really nice. We can get our snapshot from one place, our sandbox from another. These things do not overlap at all. They don't need to know about each other.
Then when we spawn, we can use the sandbox and the snapshot together. This is composability. This is the architecture that wins, even when the requirements are a little off, the implementation's a little hairy. The point here is that we had to experiment to find this. The persistent shell that we started with was like what you'd naively think of, given these requirements. I'm naive. That's what I thought of. It didn't really work. Through experimentation, we landed on this funky design where you have a transient shell, you take a snapshot. Claude and I racked our brain. We couldn't think of another example where this technique is really used, obviously. I'm sure people will think of it now that I've mentioned it. It was found through trial and error, pretty much. It balances all of these competing requirements. I'm going to emphasize this point about experimentation and point out that when you have an experiment, you have to consider the possibility of failure.
Episode III - Reversing SQLite
This last story is a little bit about an experiment that failed and what that looks like in this age of AI. This is a story about trying to ship SQLite as a persistence layer for the conversations that you have in Claude Code. Let's just illustrate this behavior real quick. I'm going to do Claude resume, and I get a list of conversations that I've been having with Claude about this project. You can see I pick one and it comes up, and now I'm ready to continue the conversation. When we started this, I just refactored this abstraction to use JSONL files. That's important, JSON, not JSONL. We could just append to an existing session file all the messages and changes that were happening. It worked fine. It actually did not have a problem. That is smell number one, it was working fine.
/filters:no_upscale()/sponsorship/eventsnotice/3ecacfe1-02d1-4d54-a048-8ee8571a77bb/resources/1EonWebinarMay21-transcript-1774373522295.png)
There's all this quality lore around SQLite. Also, I was raised at a time when people are like, don't store your stuff in files, put it in databases. The database is for data. SQLite has this sterling reputation. I didn't look that far into it. I was like, ok, SQLite, it's super well tested. It's been around forever, ships everywhere all the time, must be really good. We were also looking at using Drizzle on top of SQLite. Drizzle is an ORM in TypeScript. This thing is batteries included, super nice. You write your schema in code. It's got migrations in it. We want migrations because actually one problem we've already seen is that as the schema for tool calls evolves, we have trouble loading old conversations. We don't want to just crash when we try to load your old conversation that has an old version of the tool call in it. I'm thinking like, this is really going to help us migrate the data forward. Also, we were emboldened. We've had all the success using Claude to make these really bold changes and put stuff in. I was like, yes, let's try it. Let's see what can happen. When we say we were emboldened, I should say I was emboldened.
This is a story of 15 days that I'm never getting back. I'm not totally sorry I did it, even though I think you'll see that I could have seen some of these things coming. Starts off, we're going to launch this persistence thing. Users have been demanding this resume feature. I was holding it back because I wanted to try this database implementation. We finally go to ship it. I merged the first commit with this beautiful Drizzle schema. It's got foreign key constraints and indexes. I'm quite proud of it, you can imagine. Immediately, it has to be reverted. I totally broke the developer environment. I had a messed up dependency. This was like the very first sign that I was on the wrong track. Eventually, I cleaned that up. I merged it later that day, and we were off to the races. After less than a week, there's this GitHub issue blowing up. People are having trouble just starting Claude Code when they get this new version.
The reason is that the SQLite dependency is a native dependency in the npm ecosystem. I didn't know that much about this before I started. I don't know about you, but this is my first time distributing an npm-based app. Usually, I use Node and npm just to put something on my server. In this case, we're giving everyone an npm-based app and asking them to run it. There's this dependency called Better-SQLite. If it works for your OS and architecture, we can find the right distribution, it works great. If we can't find that, we crash. That's terrible. I went as far as, on your system, trying to rebuild Better-SQLite, if possible. Weirdly, npm totally allows this, which I was like, I shouldn't be allowed to do this. Just hilariously, this actually involved using node-gyp, GYP is Generate Your Project, which is actually a Python thing. Again, another sign I was deeply on the wrong path is when I'm checking PYTHONPATH, trying to rebuild this module for your system natively. This went nowhere. A lot of trouble. Better-SQLite author gets involved. We're really struggling here. We decide, I'm going to make this optional. Just see if we can press through the pain.
If we can run Better-SQLite, we will also give you the resume feature. If we can't, you just don't get resume. We'll see if we can make this work for a little while. Then, we also add diagnostic warnings to try to help people understand what's going on. Because once you make a feature optional, but they didn't choose whether to make it optional, that's pretty complicated and confusing. There's a lot of UI work to do on all of this. The day I knew it was over was when my friend is merging this multiprocess PR, and he didn't use the database. I was like, this is the whole reason we wanted SQLite was so that we could have safe multiprocess. He points me to some deep buried pages in the SQLite documentation about all the funky limitations of SQLite with multiprocess. It's actually a little mindboggling to confront some of these constraints. I'll try to illustrate them for you.
Once I saw this, I was like, this is just not worth it. Like, we're pressing through the pain, and for what? I posted in Slack, we're taking this thing out. I'd set it up so it was able to cleanly revert. I'd also already made it so that it was optional. We're now just over two weeks taking this feature out that we just shipped. I'd never seen anything like this before. In a way, this is the most startling example of engineering at AI speed, I believe.
Here's what we discovered through this process. In some cases, shipping revealed these problems. In other cases, this was poor due diligence on my part. There was a foundational issue here that I just didn't really recognize until after I shipped. I worked at Robinhood before I worked at Anthropic. At Robinhood, I loved the database. I just found that it was my rock. We could ship screwed up application code, and the database would protect us. It protected us with concurrency guarantees, and it protected us with data integrity guarantees. However, the constraints of a financial firm are completely different from the constraints of a developer tool like this. The worst thing that can happen with Claude Code is you go to start it, and it doesn't start. I don't know about you, but I can't really do anything anymore if Claude isn't there to help me. People got pretty upset when Claude crashed. This is a case where availability totally trumps consistency. For a financial firm, it's exactly reversed.
The other thing that I just didn't know is that native dependencies basically don't work in the npm ecosystem. You can install them on your server, that's fine. If you need to distribute something, I would say just don't do it. pnpm, which is a very popular package manager, just doesn't really work with this. Again, this is a case where the user's running it on their app. If they can't start, we don't even get visibility into what's happening. The next thing is SQLite is an odd beast. I came from the world of Postgres. I thought SQLite is SQL. How different is it? I definitely learned the difference between the SQL spec and the nice features of Postgres. Let me just show you one example here. SQLite's locking is not like Postgres locking. Postgres can lock individual rows and tables. SQLite locks the whole database when you write to it. Here's one example. We're going to begin two transactions, and we're going to both read and write in the two transactions.
First transaction reads, second transaction reads. First transaction writes, second transaction goes to write and fails because the first transaction has already written a row. This is not retriable. This is not something that SQLite will handle for you. This becomes application code that you now need to deal. What are you going to do? How many times are you going to retry this? Users have 15, 20 versions of Claude Code open at a time on their terminal. This can get sticky really fast. Sometimes these sessions are days old. We might have three version skew, all three running against the same database. I'll talk about some of those problems as well.
I was really excited about migration. This is one reason why I thought SQLite would be a good answer for us. It turns out migration is also really tricky, especially when you're doing it on a machine that you don't have observability into and you don't really control. Basically, we need to do migration at startup. You start Claude Code, the last thing in your mind is that your data's going to get migrated. Even the slowdown is problematic, but there's something much worse here. You can't add constraints to a SQLite table.
In Postgres, you can just slap an extra foreign key on there. In my initial implementation of this schema, I forgot to add ON DELETE CASCADE. That just really bothered me, of course, so I needed to go fix it. I made a little demo here just to show you that when you run a migration, you actually have to turn off all of the constraints in SQLite. It can't really handle this. You turn off all the foreign key constraints, you have to delete and recreate your table, or I should say, first you recreate it, then you delete your table. While all the constraints are turned off, you can put bad data in your database. You actually don't even get the integrity guarantee that you sought originally. This is a bit of a contrived example, but there are other real-world cases that make this really hairy.
Then, the very last thing is like, this turned out to be super ironic. I work on the auto-installer, some of the greasy innards of Claude Code. The whole thing I wanted from this was safe multiprocess. It turns out that like, this actually makes multiprocess more dangerous. It's very easy to write bugs where you have two different versions of Claude Code and one overwrites or does something unexpected because there's a new version that has changed the schema. I know there's ways to build tooling and there are ways to train developers to not confront these problems, but they're very common. In this case, I just made a little example where one version is running against one schema and a new version is running against a new schema.
If the old version does anything like SELECT * and then writes back, it'll write bad rows. It'll overwrite data that the new version's written. It's not as simple as just making sure your schema's backwards compatible. You also have to be really careful about what you ever do in your application code. It takes a very mature software project to have real guards against this. You need a lot of intelligence about what's possible and not in SQL. Let's dump all that. We'll go back to JSONL. It works everywhere. This is what we use to this day. It's deeply imperfect. If you try to resume in Claude Code, you often end up with funky situations where you don't quite see what you expected to see. There's still some problems with this, and a lot of them are caused by data integrity issues, but at least you can start, and that's the most important thing. Was this a mistake? I think it would have been. It definitely would have been, but given how fast all this went, I'm glad we tried it. I'm not saying that SQLite is bad. I think we'll probably end up using it in Claude Code, but probably not for this, probably for something like settings and probably something with a schema that is really not expected to change.
Synthesis
Let's try to put all this together. What can we learn about engineering in the age of AI? In all of these cases, we learn things by shipping. Starting off, we were told that rebuilding input was a bad idea, but it wasn't. It was exactly the right idea, even though we didn't see all these Unicode messy edges coming. For shell, yes, user environments are really tricky, and we try to support all of them, and we do it imperfectly, but the tradeoffs here are worth the pain. In SQLite my main takeaway is like, don't ship a native dependency to npm. That's just too hard. The architecture here is really what determines the outcome of these projects. Cursor architecture was everything self-contained, no dependencies. That's amazing. That's amazing for Claude. It's amazing for the developer. You can rip through this stuff, even when it gets complicated. Shell is all about the dependencies.
/filters:no_upscale()/sponsorship/eventsnotice/1302f11a-f90f-4a79-96d1-3dd20d032144/resources/1HarnessWebinarMay28-Transcripts-1776246863928.png)
In that case Claude didn't help us quite as much. Also, Claude's idea about what would work in the Node ecosystem, that tended to be wrong. Then in SQLite this is like a fundamental miss on, what are we trying to safeguard here? Availability is more important than consistency in this app. How do we know when we're on the right path? All of the development was painful here. These Unicode bugs that kept popping up, that did not feel good, even though I'm presenting it as a win. For shell, it wasn't ever clear that we were on the right path. Even the solution we have now feels a little hacky. With SQLite, it just got worse and worse every step. From the very get-go, it was pain and it just multiplied. You can have different outcomes when you experiment. I've got to underline that point. If you're not having failures when you experiment, you're not experimenting enough. That's one of the expected outcomes. In some ways, like a clean failure is a little easier to deal with than this situation with shell where you muddle along and it's not obvious that you're on the right path.
Either way, the core insight here is that you can test your architectural decisions. Thinking about this, I really realized like this is different. We used to spend a lot of time debating, design docs, design discussions, extensive requirements, POCs. We had to do this because we knew that the actual implementation would be really expensive. That was the bottleneck. That's what we're optimizing for. Now we can throw this away and we can find out. You'll see in two of these cases, both in the Cursor case and in the SQLite case, the outcome defied conventional wisdom. The conventional wisdom says SQLite is where you should put your data, but that turned out to be not true for us. In the traditional loop, you spend time on these requirements because you know this thick middle part is going to be the implementation and you want to save that. That's what you don't have, is developer hands to do this stuff. In the new world, the implementation is not the bottleneck.
In a day, you can pretty much pump out any feature with Claude Code's help. The question is, what's it going to take to get that in production? Then, how are you going to collect feedback on that to guide your next step? The only real advantage you can have in this world is the speed at which you learn. It's really not the speed at which you ship.
What are you going to do about AI, especially for a project that's fully AI enabled? One thing that we can all do is we can always ship faster. I learned this back in my days all the way at Facebook. I've held it with me ever since. Shipping speed is the key to having good software. The reason why is that, if you're going to get better, you're going to need to change. The faster you can change, the faster you can get better. Remember how I said Claude Code ships all the time? That is not a side point here. That is the point. That is what enables us to move really quickly. The other thing is like, CLI is a really useful form factor for this. It's much easier to deal with. It's much better for Claude to program. It's easier for the user to program, and for the AI to collaborate with you. I would ask, not all of us have the luxury of shipping a CLI, but what can you do to simplify your dependencies, remove ornamentation, and give power in place of like filigree? What's your playbook going to be?
First thing is, optimize your delivery cadence. You want to try to get to continuous deployment. That is the gold standard. We'd like to do that, not just internally, but for some of our external users as well. We're just trying to reduce the cycle time. That is the most important, biggest lever. Second thing is like, do put things in that make it easy to reverse course. If you're experimenting, you're going to have things that need to go backwards, so feature flags, modular architecture, wherever you can find it. Then the last thing is, we invest really heavily in our build, release, and distribution. If you ship a bad release, ideally all you have to do is move a pointer to get back to a good known state. You do not want to have heavy processes for backing out a bad change, if you're moving this fast.
The last thing is, you have to unship. Instead of spending a lot of time on your product roadmap, and making sure that each feature makes sense in your whole product suite, I would say just ship everything, and then edit later. It actually requires a lot of suppression of ego. Because at the end of the day, you and your friend might ship very similar features, and you're going to have to decide, is one better, or do these have to come together? I think you can see that in Claude Code. We have a bunch of overlapping features. We're still figuring out how they all play together.
What's next for Claude Code? I think we have this basic loop running, but the AI is quickly driving the implementation cost to zero, especially as the model gets better. Really, any change I can think of, I can prototype by the end of a single day. The new bottleneck is really not about this. It's actually about the longer loops that we all experience as part of the whole Software Development Life Cycle. This is things like using AI to generate actionable insights from bug reports. It's about having very sensitive evals so that when you make a small prompt change, you can detect whether this is helping or hurting you.
The last one is just continuing to invest in the way that you build, release, and distribute. Making sure your CI runs really fast. Making sure that you have multiple releases a day, if you can. These are the things that you really need to work at this speed. Claude Code is a special case here. We're always dogfooding our own product, and it really guides our intuitions about what the right things are. It also has this compounding effect. I did want to take a moment and say, all of us need to be dogfooding. If you're not using AI, not just to accelerate your development, but to accelerate all of your development processes, how you write a design doc, how you interpret feedback, all of these things, even like your planning process, these things are all optimizable with AI. I really hope everyone here is working on figuring out how to best apply this technology, because, again, this is where the new bottlenecks are.
The Takeaway
Different stories here. I wanted to get here and tell you like, it's really simple. Just keep your code really simple. Obviously, I did a bunch of spelunking that proves that it's not really that simple. That's not the point here. The point is that when the implementation cost goes to zero, the feedback loop becomes everything. Optimizing that feedback loop is the way that you can work at AI speed.
Questions and Answers
Participant 1: I didn't get the SQLite. Did you guys catch it before rolling to production or users actually started to report issues and they have to roll back the SQLite migration?
Adam Wolff: We had to take it out. We had it in the product. We shipped it for about two weeks and then we removed it.
Participant 1: Did you do something about not getting issues like that for their own production, or testing on different operating systems, different combinations?
Adam Wolff: Yes. Our test coverage is limited. We have a very strong security environment at Anthropic. It's pretty hard to set up something like a Windows machine. We do test with Windows, but it's tricky. On our developer machines, it was hard to tell how much of a problem that these native dependencies would cause.
/filters:no_upscale()/sponsorship/eventsnotice/7dd71c7c-4b0e-4760-b97d-232ac1816637/resources/1NeuBirdWebinarJune25-Transcripts-1777458459989.png)
Participant 2: I wasn't quite clear on, was the reason for you to take out SQLite because the other developer found somewhere in the documentation that that was not the right thing to do or did you see some users being impacted by the use of SQLite as well?
Adam Wolff: It's a combination of things. To be clear, it's not just like, here's a bug in SQLite that is not workaroundable. It's more just like, when you look closely at what you get from this abstraction, it's not giving you what you really wanted, which was safety. Sure, I could sit down and we could puzzle it through and write some code that tests it out, but that's not what I wanted. What I wanted was something bulletproof that would make it easier to deal with multiprocess concurrency, and this was not hitting that far.
Participant 3: When you're switching back from SQLite to JSONL, you mentioned there are some limitations and issues. Could you talk more about like, what are some of the challenges that you see and what are some of the things that you guys have done to solve these problems?
Adam Wolff: The conversation is actually more complicated than you might think. It's a DAG. It is not linear, because you can go backwards in the conversation and branch. There are a bunch of ways you can do that. The basic data integrity guarantee that you want is that each message has one and only one parent. We can't actually make that guarantee, and you'll see bugs in the resume menu because of this. The other thing that just bothers me, I haven't really seen it in practice, but the other problem that you have is like, you actually aren't guaranteed that file writes are atomic. We're appending to a file. If those messages get too long, they could get buffered and interleaved, and you could end up corrupting lines in your file. I still don't know how big a problem this is in practice, but I know that's a landmine that's waiting for us for sure.
Participant 4: How do you use the tools, your relationship between yourself and the AI generating your code? Because, clearly, you're making a lot of these architectural decisions. You're driving the simplicity, or you're driving the features. When you go out to implement one of these features, do you just give it a prompt and let it run, or do you shape the whole process?
Adam Wolff: There's a lot of technique that comes with using these agentic tools, and the main point I want to make is that my technique is always evolving. Just a couple weeks ago, I did a little experiment where I had Claude look at all of the saved conversations in the .claude directory, and point out what prompts lead to lots of autonomous work, and what prompts don't, and how do I know when a conversation's reaching a dead end? Claude actually had a bunch of good points it made. If you give a design requirement along with a constraint and the reason why, you get much better output than if you just say, do this thing. It also said whenever I get to the point where I'm saying it's not working, I should just quit the conversation, because you need to take a new approach.
If you just find yourself saying, "We tried that, it didn't work". You're not going to get very far. You need to have a fresh approach. The meta here is you need to keep trying to evolve this and keep trying to use the tool better. Personally, I usually start by saying, "Claude, we're working on persistence for these conversations. Let's brainstorm some ways this could work. What should our steps be?" I usually have an idea in mind and I guide the conversation, but I also like to shape that process. The techniques will keep evolving as the model frontier moves, but the important thing is to stay awake to what you're doing. It's really easy to basically have a bad or abusive relationship with Claude. You need to really think about how you're treating Claude and how Claude's treating you.
Participant 5: How have your failures shaped your prompting practices in how you approach new problems?
Adam Wolff: Sometimes I will be looking at main and I'll be like, what is this crap code? How did it end up in here? Then everybody else is like, it's my PR? Because like, it's very hard to force yourself to review every single thing that Claude writes. I also have gotten in little lazy places where I stopped using my editor, I tried to use Claude even to make simple variable renames and stuff like that. That's a mistake, I think. There are a lot of cases where you can be faster doing something yourself or changing one part and then having Claude come back and do the rest. I've definitely had data spelunking episodes where Claude and I both hallucinated that we had some gigantic bug that was slowing us down. Then this led me on a wild goose chase. I've become a little more skeptical. I look for multiple signals that I'm on the right path.
Participant 6: You have described a great way how to develop very fast with AI, but you also worked at Robinhood, in finance. How do you see methods like these where you unship things and just try things out in something like the finance world where you have a lot more compliance and red tape to work with?
Adam Wolff: I haven't thought in depth about this. The one thing I'll say is like, there's so much we build that is not the product we ship to production, and all of those things can be optimized with AI. Every single thing you do can be assisted by AI, whether it's having a custom Slack bot, or having a really nice PR review process, or automated deployment scripts, you name it. Probably, if I were in finance, the very first things I'd go after would be all of the internal tools. Those are less under the enthrall of compliance. There's so much juice there in terms of what's actually time consuming when you work in finance. So much of it is these human processes that can be accelerated with AI.
See more presentations with transcripts