
Tomofun, the Taiwan-headquartered pet-tech startup behind the Furbo Pet Camera, is redefining how pet owners interact with their pets remotely. Furbo combines smart cameras with AI to detect behaviors such as barking, running, or unusual activity, and alerts owners in real time. At the core of this capability are computer vision and vision-language models that interpret pet actions from the video streams.
Originally, Furbo’s inference workloads were hosted on GPU-based Amazon Elastic Compute Cloud (Amazon EC2) instances. While GPUs provided high throughput, they were also costly because the always-on inference needed to support real-time pet activity alerts at scale. To reduce costs and maintain accuracy, Tomofun turned to EC2 Inf2 instances powered by AWS Inferentia2, the Amazon purpose-built AI chips. In this post, we walk through the following sections in detail.
Challenge: Reducing GPU inference cost for real-time vision-language models at scale
Running advanced vision-language models like Bootstrapping Language-image Pre-Training (BLIP), detailed in the original paper, were hosted on GPU instances and proved less cost-effective for always-on, real-time inference workloads at scale. The challenge was twofold: Tomofun needed to sustain cost efficiency for nearly continuous pet behavior monitoring across hundreds of thousands of devices, while also maintaining model fidelity and throughput. Tomofun needed to do this without rewriting large portions of the BLIP code base already optimized for PyTorch.
Solution overview
Before diving into the architecture, the following diagram provides a high-level view of how the system processes pet behavior detection at scale across AWS services.
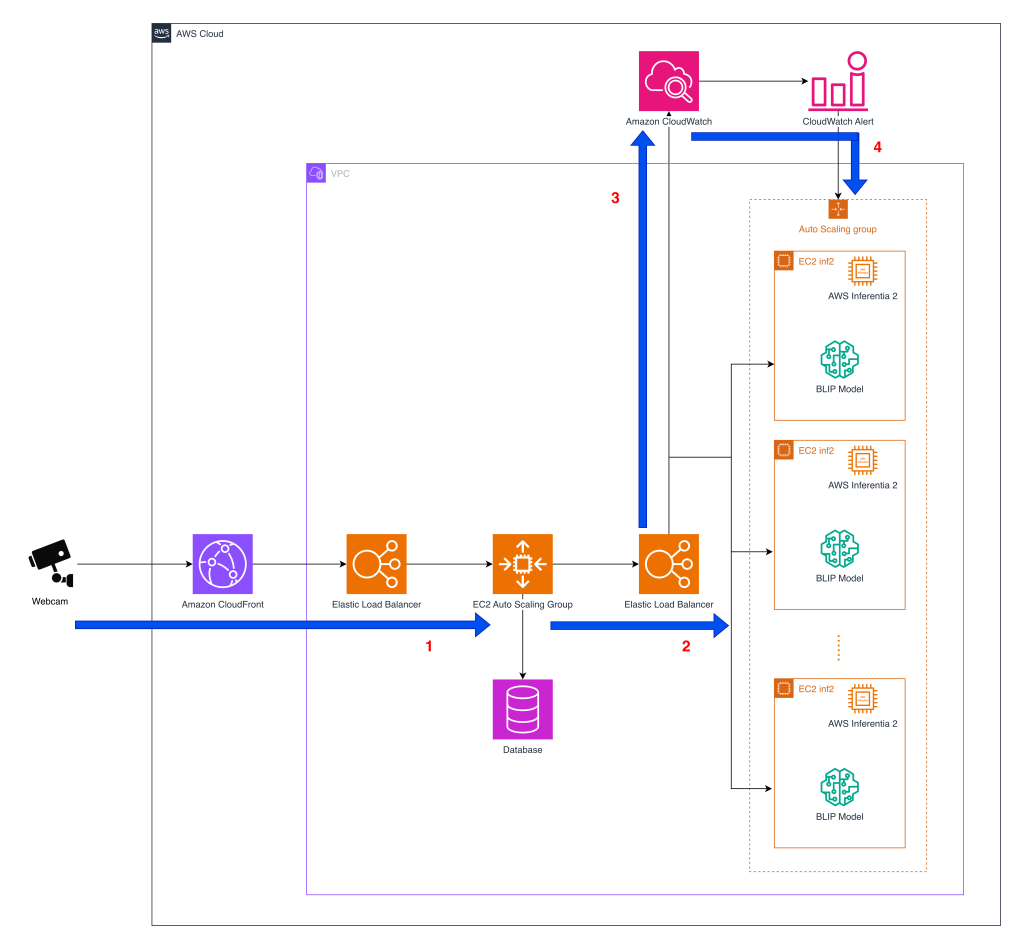
- Webcam interaction – Furbo’s API sits at the center of Tomofun’s pet-behavior detection service, orchestrating image streams from customer’s pet cameras to inference endpoints in AWS. The diagram shows the architecture of Elastic Load Balancing (ELB) and Amazon EC2 Auto Scaling group implemented using EC2 Inf2 instances providing scaling as the inference volume grows in real-time. When a camera captures a frame, the data is routed through Amazon CloudFront and an ELB to the first layer of the EC2 Auto Scaling group that hosts the pet-behavior detection API servers. After the API layer processes each request, it forwards the image to a second-layer Auto Scaling group dedicated to running model inference.
- Model inference – After processing, the images are forwarded to a second layer EC2 Auto Scaling group containing inference instances. Inside this group, containers host the BLIP model, which can run on Inferentia2-based EC2 Inf2 instances. The BLIP model components compiled using the Neuron SDK are loaded into containers on Inf2 instances. In the early implementation, Furbo’s API routed inference calls exclusively to GPU containers, but now it can also direct requests to Inf2-based containers without changing the upstream API or downstream alert logic. This architecture allows Tomofun to direct inference requests to and switch between GPU and Inferentia2 backends in real-time. This maintains high availability and gives them the flexibility to scale cost-efficient inference while preserving the same API surface for Furbo users.
- Metrics collection – Amazon CloudWatch monitors key operational metrics across the inference fleet, including latency, throughput, and error rates. These signals provide the observability needed to detect performance degradation early and ensure that service-level objectives are met as traffic patterns shift throughout the day.
- Scaling with Demand – The ELB dispatches requests to the available instances within the Auto Scaling group, which manages the size of the instance pool size based on the incoming request count as the CloudWatch metric. This metric-driven approach is adopted because the throughput benchmarks for each instance type have already been established through stress testing, so scaling decisions can be driven directly by the volume of image requests. The result is an architecture that scales cost-efficient inference capacity in real time, maintaining high availability as demand grows.
Improving BLIP on Inferentia2
Before diving into the model details, the following diagram provides a high-level overview of the BLIP architecture and how its core components interact.
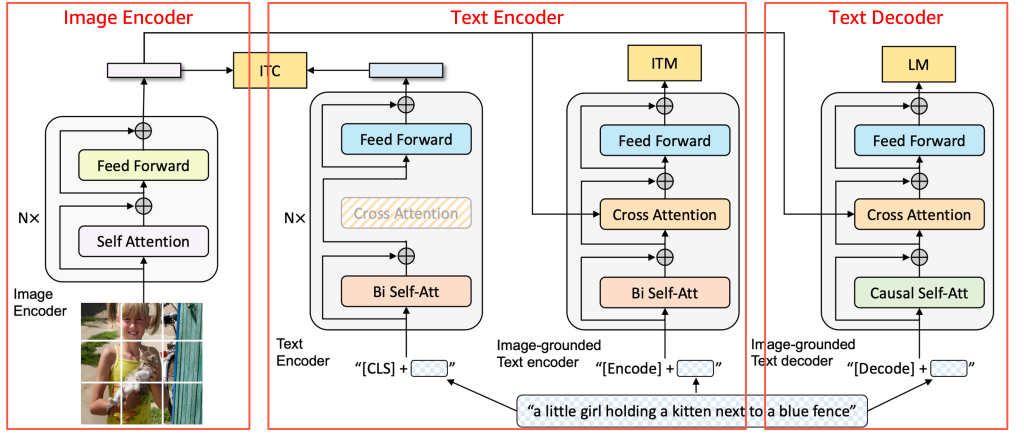
Source: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, 2022 https://arxiv.org/pdf/2201.12086
BLIP is composed of three components—the Image Encoder, Text Encoder, and Text Decoder, as shown in the image. For support on Inferentia2, models can be broken into components and wrapped to fit input and output shapes. Tomofun applied this method to BLIP, creating lightweight wrappers for each of the three components of the BLIP model so the original architecture remained unchanged. Each component was compiled independently with torch_neuronx and then combined into the inference pipeline, allowing inputs to flow sequentially. This modular approach maintained compatibility with Inferentia2 without altering BLIP’s pretrained logic.
Original model code
The first step is to isolate the original BLIP Text Encoder so it can be compiled without modifying its internal logic. The TextEncoder class is a thin wrapper around the original submodule (model.text_encoder.model) that standardizes the forward output by returning only the primary tensor. This makes the component straightforward to trace and compile with Neuron while preserving the original architecture.
During the compilation phase, the original model (model.text_encoder.model) is passed directly into torch_neuronx.trace() and compiled into a Neuron-optimized TorchScript artifact, without modifying the pretrained BLIP logic.
Wrapper code
A wrapper is needed because the torch_neuronx.trace() API expects a tensor tuple of tensors as input and output. To avoid rewriting the model, lightweight wrappers act as an adapter layer that reformats inputs and outputs while keeping the original architecture unchanged. This approach minimizes code changes and allows the compiled components to integrate seamlessly into the existing inference pipeline.
The wrapper is used only at deployment to load the compiled model and format I/O, so it fits the existing BLIP pipeline.
- Compile: use the original model (
model.text_encoder.model) - Deploy: use
TextEncoderWrapperto run the compiled model
This keeps the original code unchanged while making the compiled model easy to plug into production.
Model compilation for Inferentia2
In the following code snippet, model.text_encoder.model represents the unmodified Text Encoder submodule, which is compiled into a Neuron-optimized TorchScript format.
To compile BLIP components for Inferentia2, Tomofun defined a trace function that automates the conversion of GPU-trained PyTorch models into Inferentia-optimized artifacts. The process begins by preparing pseudo input tensors that represent the expected shapes and data types of the model’s inputs, which guides the tracing process. After the inputs are defined, the function calls torch_neuronx.trace() to compile the BLIP sub-model for Inferentia execution, producing a Neuron-optimized version of the original code. Finally, the compiled artifact is saved with torch.jit.save, making it ready for deployment on Inf2 instances. This three-step flow—loading the wrapper, providing pseudo input data, and compiling with Neuron—makes sure that Tomofun can migrate BLIP’s TextDecoder and other components without changing the original model code.
Model deployment on Inferentia2
In the deployment phase, the compiled submodules are loaded through wrapper classes to assemble the final BLIP inference pipeline. This separation creates a clear workflow where the original model components are used directly for Neuron improvement during compilation, while the wrapper classes handle input and output formatting during inference to ensure compatibility with Inferentia2. The deployment phase code is as following:
models.text_encoder = TextEncoderWrapper.from_model(
torch.jit.load(os.path.join(directory, 'text_encoder.pt')))
This design preserved the original BLIP architecture without modification while meeting the Neuron SDK’s I/O interface requirements through lightweight wrapper classes. It also enabled a modular, component-level workflow for both compilation and deployment, allowing each BLIP submodule to be compiled and managed independently. As a result, the use of model.text_encoder.model is essential during the compilation phase for direct Neuron optimization, whereas the wrapper classes handle input and output formatting during inference to ensure smooth execution on Inferentia2.
Stress testing
To validate performance at scale, Tomofun conducted stress tests simulating real-world Furbo camera workloads. Each video stream triggered action detection queries such as “Is the dog barking?”, “Is the dog playing?”, or “Is the dog chewing furniture?”. These tests confirmed that Inf2 instances (one Inferentia2 chip, 32 GB memory) could sustain the required throughput while maintaining low latency. In addition to accuracy, the tests highlighted that the Inf2 deployment could handle simultaneous requests across hundreds of thousands of devices, making it well-suited for Furbo’s always-on global customer base. Importantly, the comparison baseline was running GPU-based instances with an on-demand pricing model, which reflected the cost Tomofun was paying before migration to Inf2. By migrating from those GPU on-demand deployments to Inf2.xlarge instances with Inferentia2, Tomofun achieved 83% cost reduction without compromising performance.
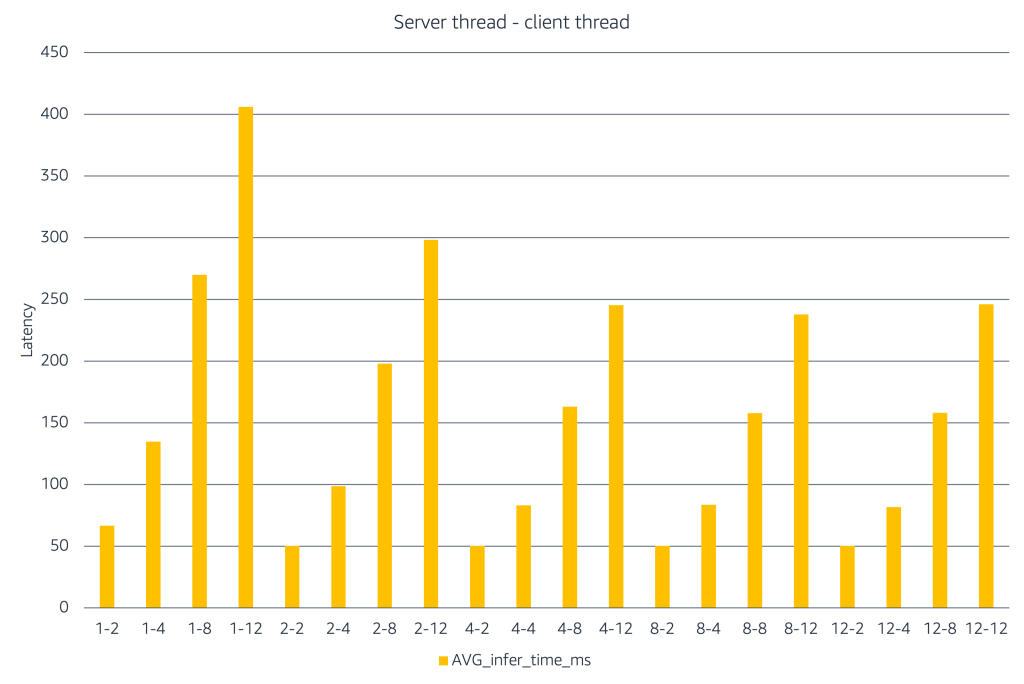
The chart illustrates how inference latency changes as server and client concurrency increase. The X-axis represents combinations of the labels represent #server threads – #client threads to simulate performance under different load scenarios. When only a few server threads are available, adding more client threads causes latency to rise quickly. Increasing the number of server threads helps absorb this load and keeps latency lower. At higher concurrency levels, latency increases and gains level off, indicating saturation. This experiment shows that teams should use load testing to identify the right balance between client concurrency and server capacity, and then limit concurrency to that range to achieve the right latency–cost tradeoff in production.
Conclusion
By migrating BLIP inference on AWS Inferentia-based EC2 Inf2 instances, Tomofun reduced their Furbo application deployment costs by 83%. The transition from GPU to Inferentia2 was seamless, as the migration required only lightweight wrapper classes and left BLIP’s core logic untouched. Testing confirmed that using Inferentia2 not only reduced the deployment costs, but also maintained high throughput for real-time inference at scale. Tomofun plans to migrate more workloads to Inferentia2 as it supports workloads beyond vision-language models, such as audio event detection for barking recognition and potential future integration with large language models to enhance pet-owner interactions. Additionally, the adoption of AWS Deep Learning Containers (DLCs) has been scheduled into the roadmap as a next step, using pre-built, improved container images to simplify dependency management and streamline inference workflows.
To learn how to implement similar improvements, explore the AWS Neuron documentation and examples you can reference AWS Neuron Document. You can also visit Furbo website to explore Furbo’s AI-powered features and see how the Furbo ecosystem keeps your pets safe.



