
🐍 Newsletters
AI Snake Oil
39 min read
Open-world evaluations for measuring frontier AI capabilities
Introducing CRUX, a new project for evaluating AI on long, messy tasks
Introducing CRUX, a new project for evaluating AI on long, messy tasks
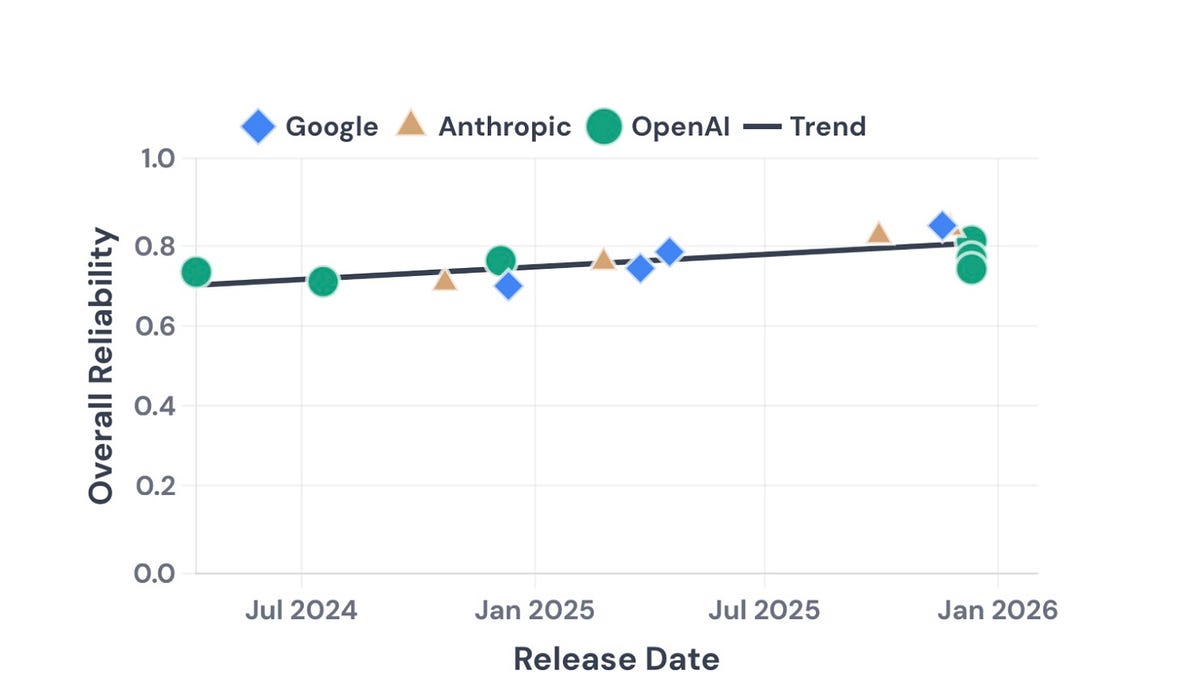
Quantifying the capability-reliability gap
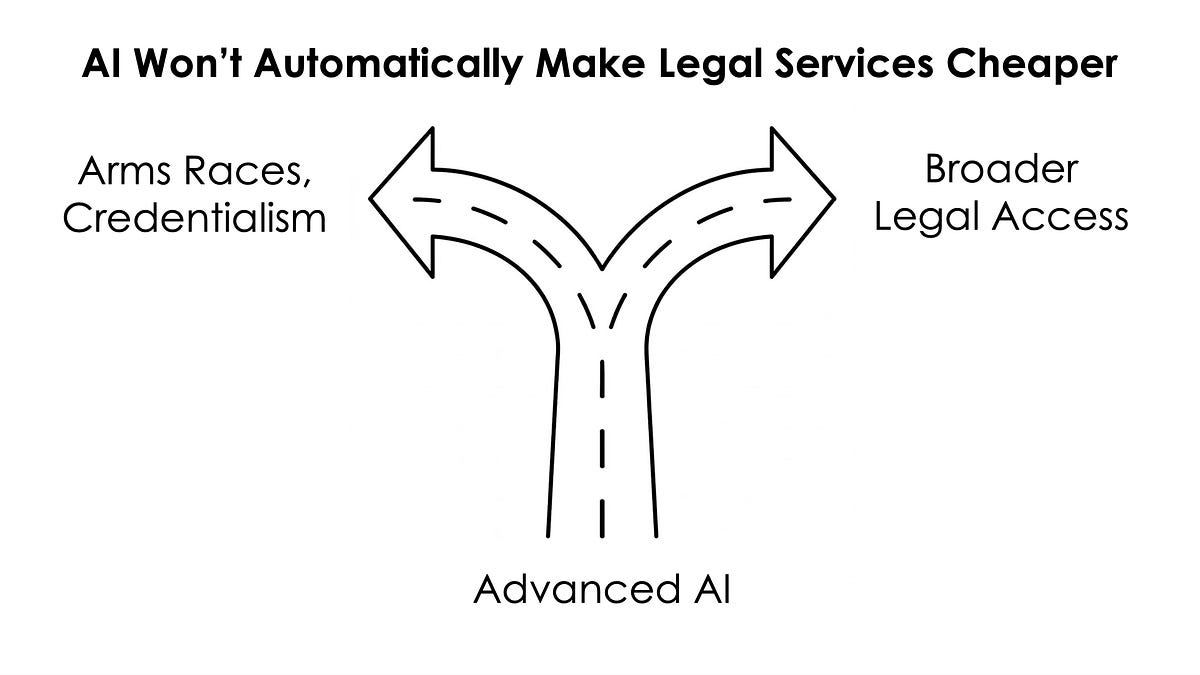
Applying the AI as Normal Technology framework to legal services
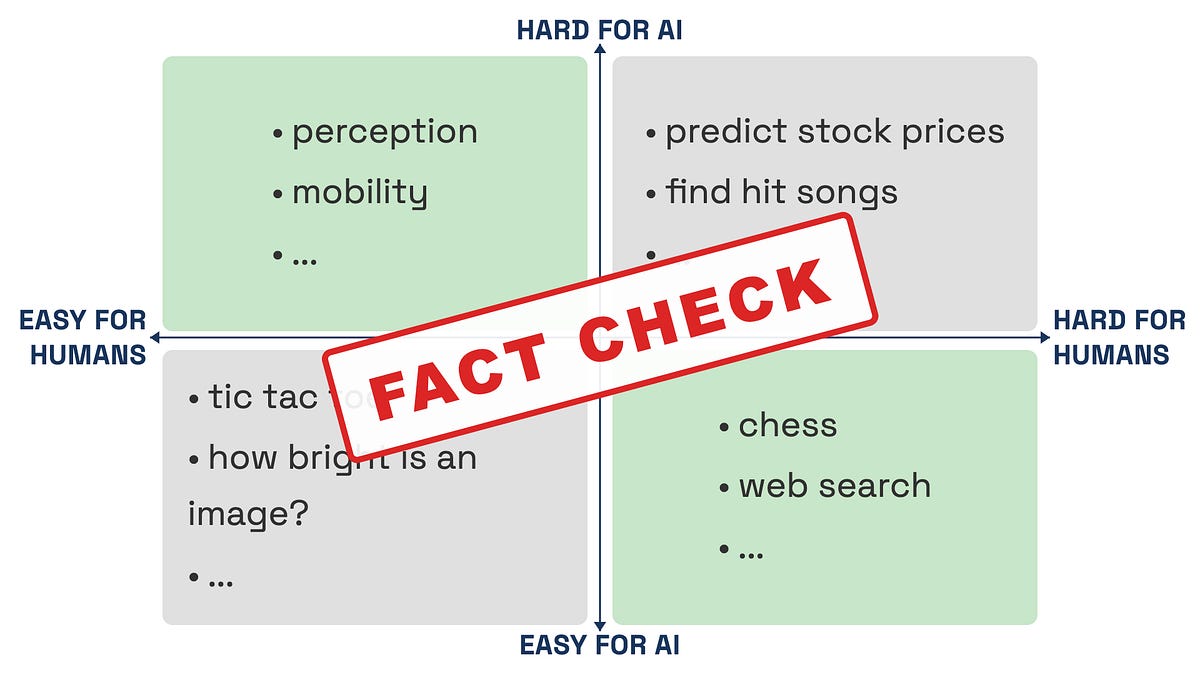
This famous aphorism is neither true nor useful

And a big change for this newsletter
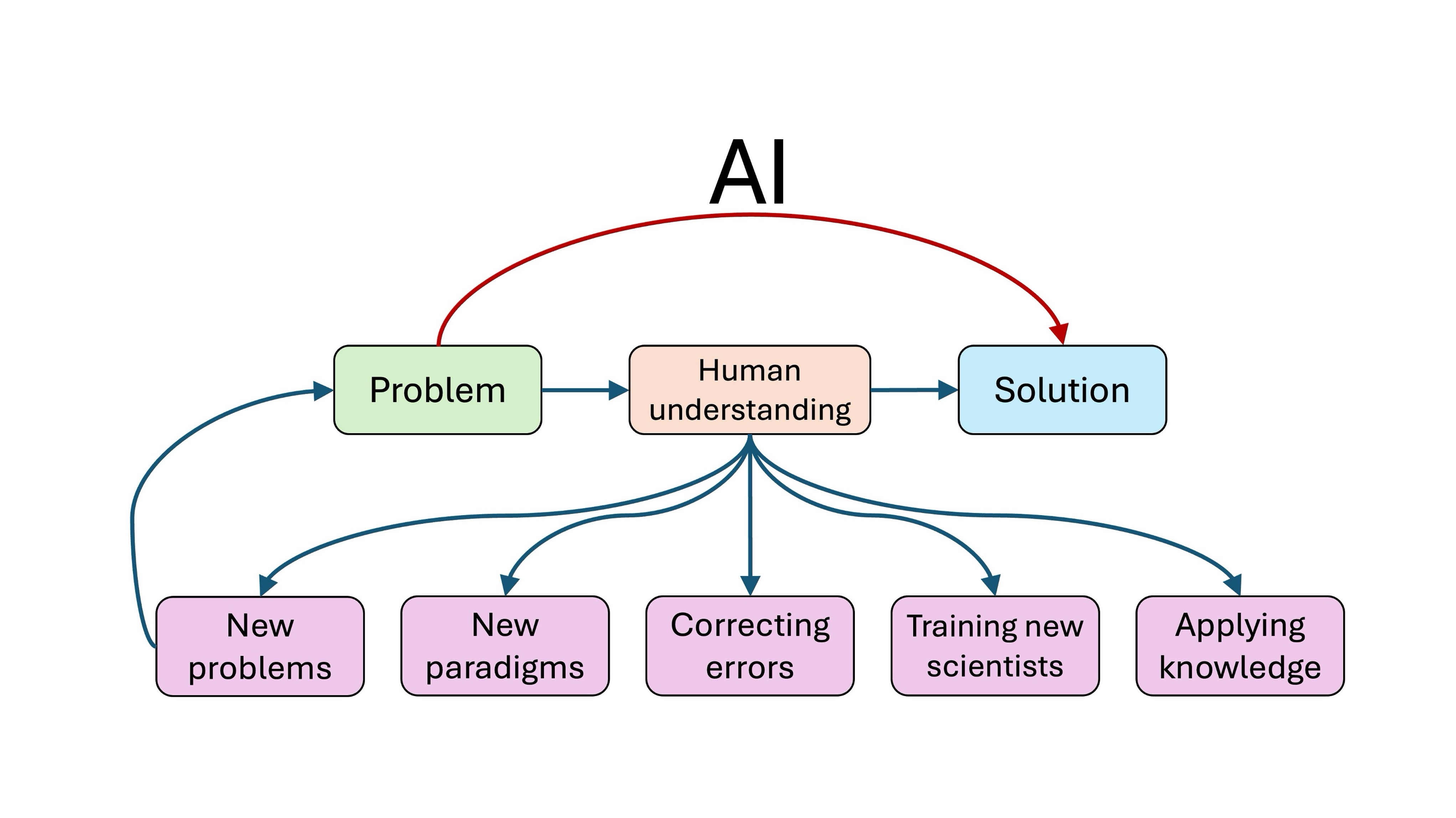

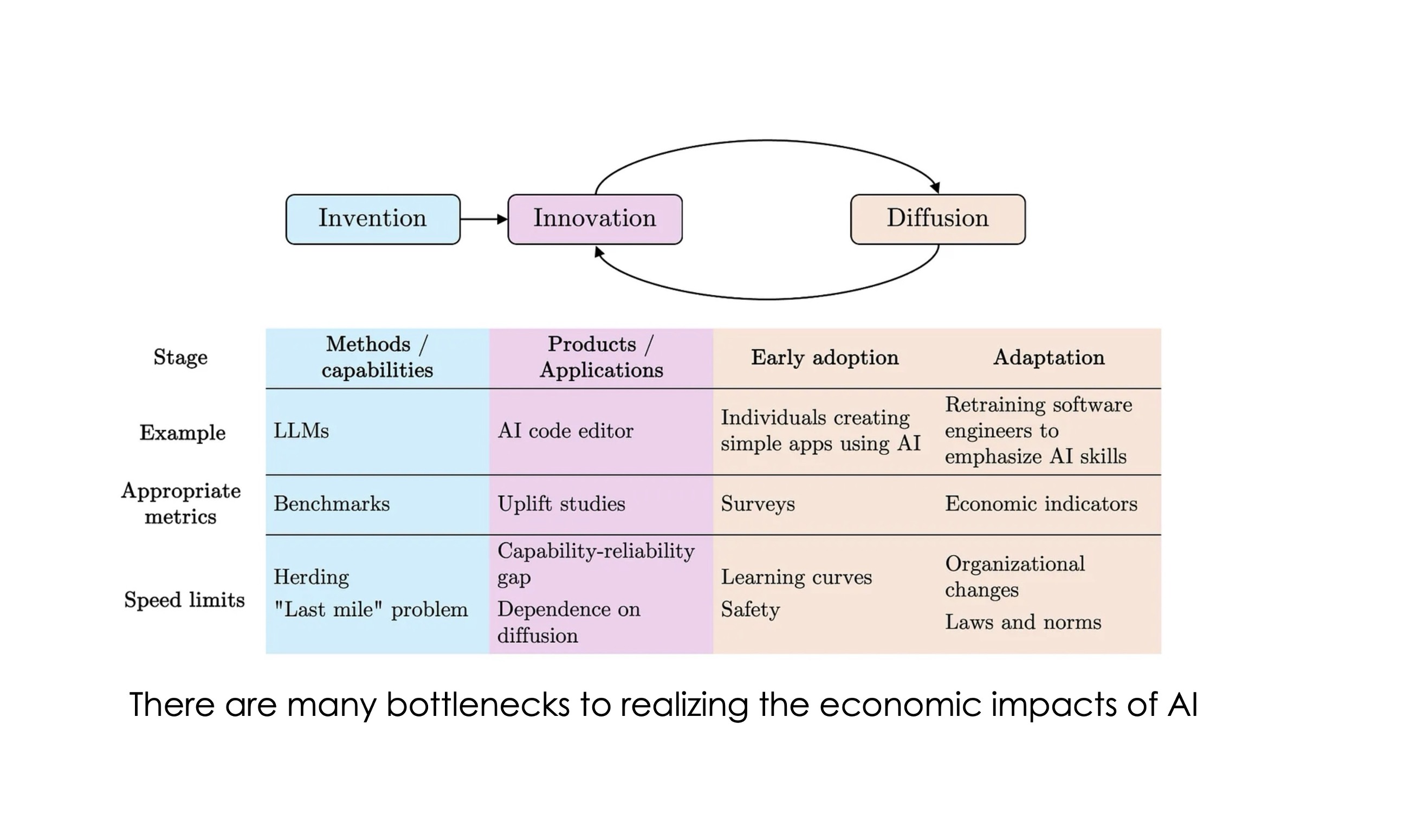
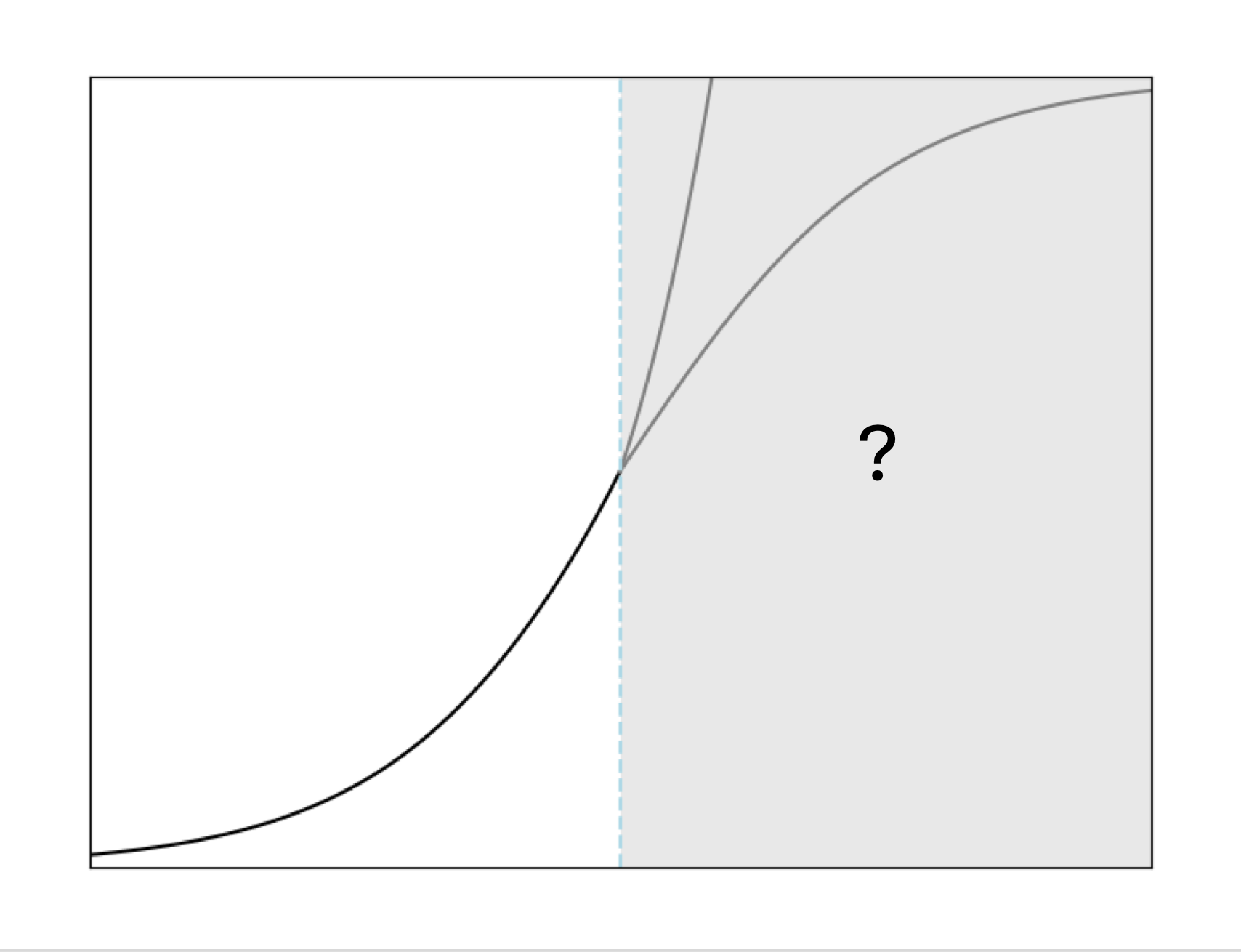
There is no capability threshold that will lead to sudden impacts
A new paper that we will expand into our next book

Making sense of recent technology trends and claims

Technology Isn’t the Problem—or the Solution.

Seemingly minor technical decisions can have life-or-death effects

What's in the book and how we wrote it
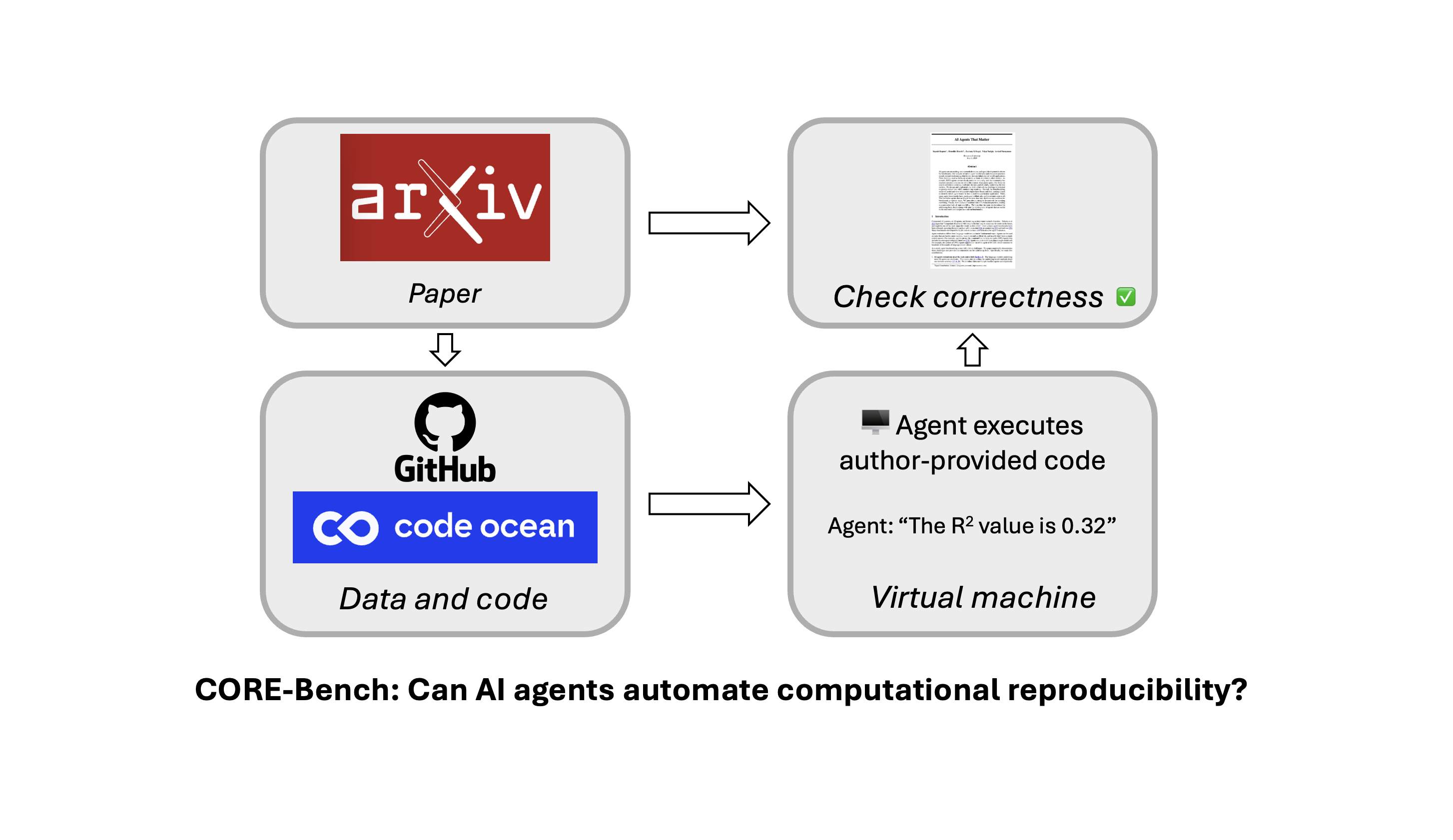
A new benchmark to measure the impact of AI on improving science

The book was published September 2024
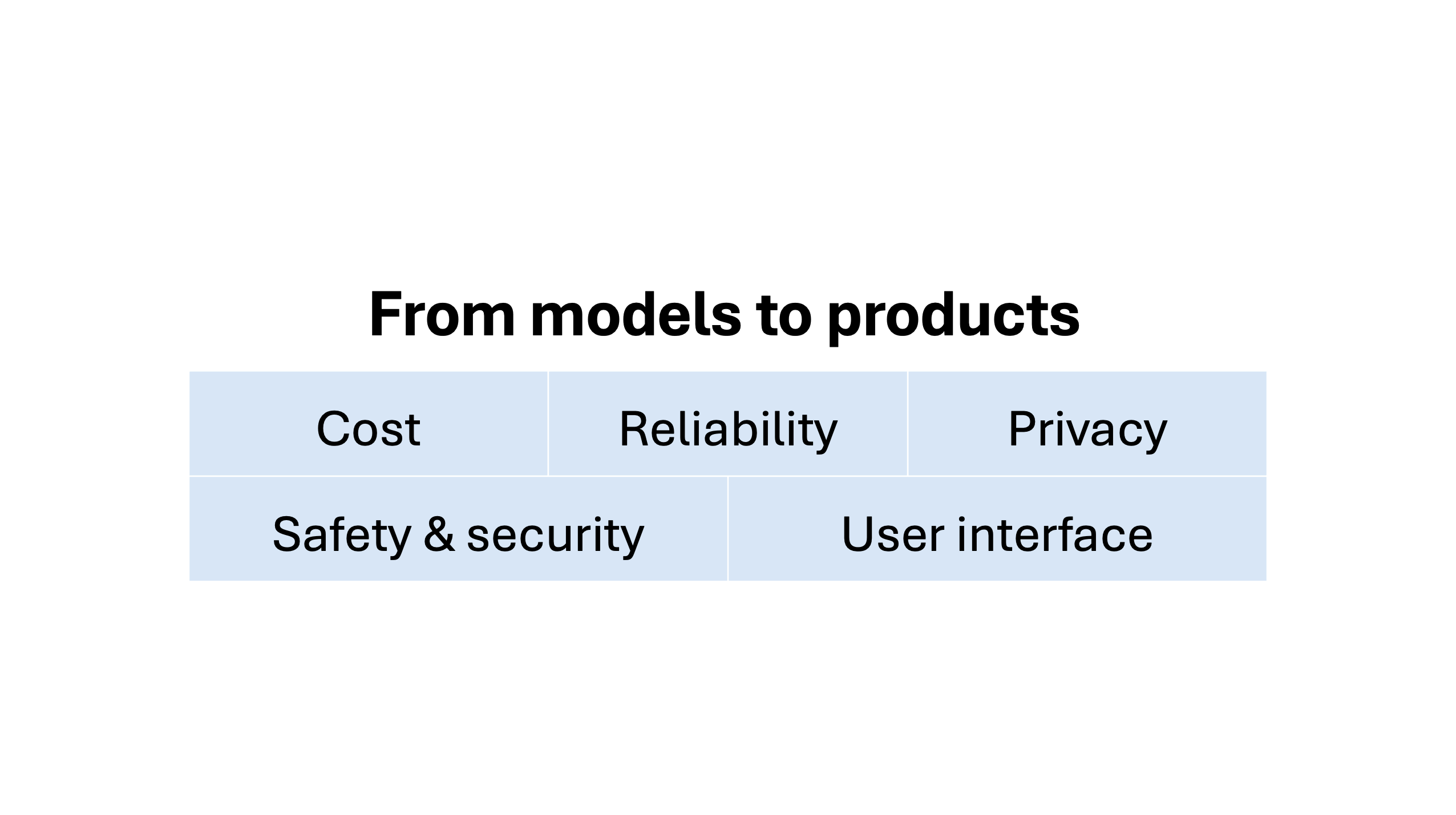
Turning models into products runs into five challenges
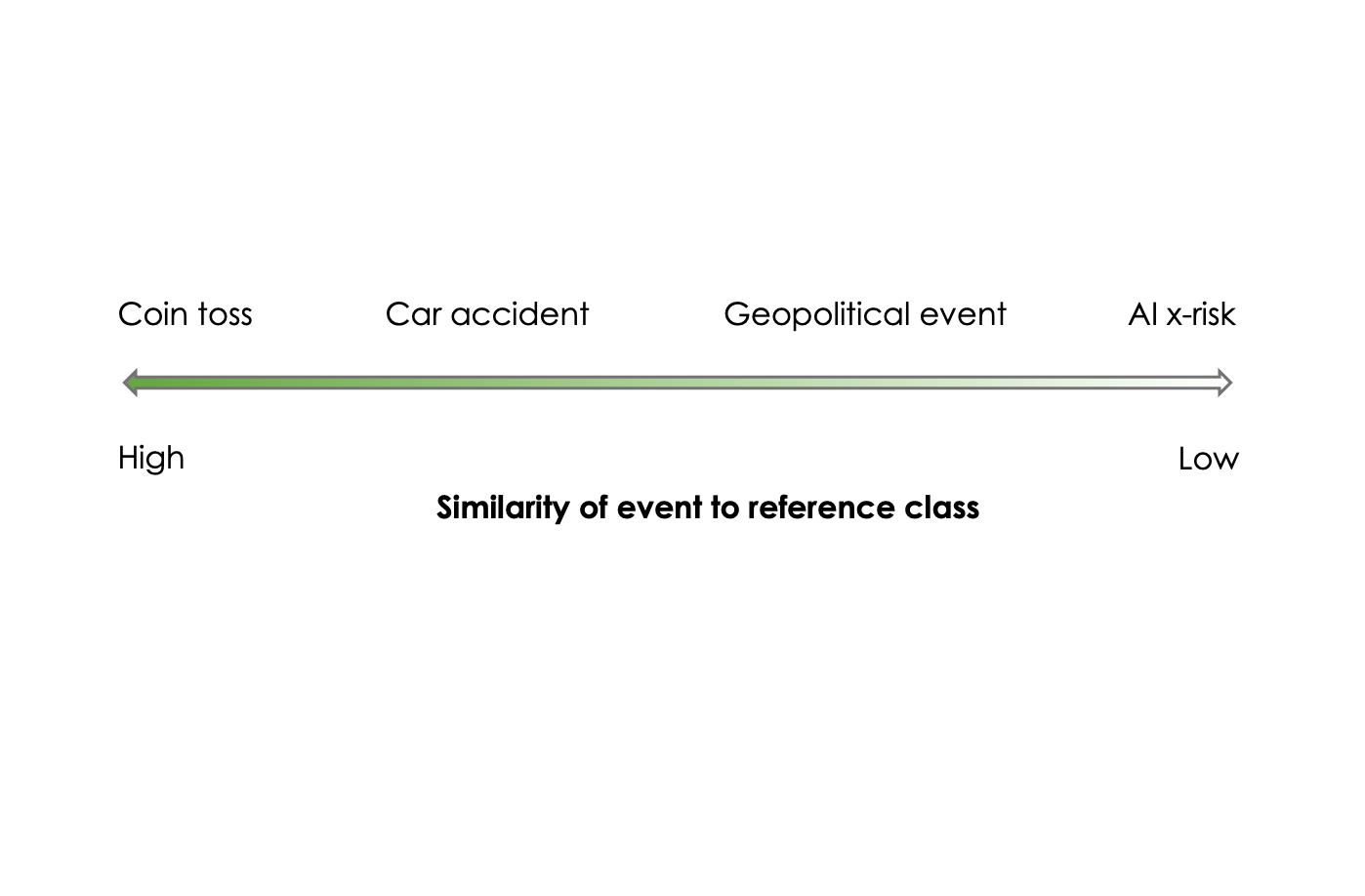
How speculation gets laundered through pseudo-quantification

Rethinking AI agent benchmarking and evaluation
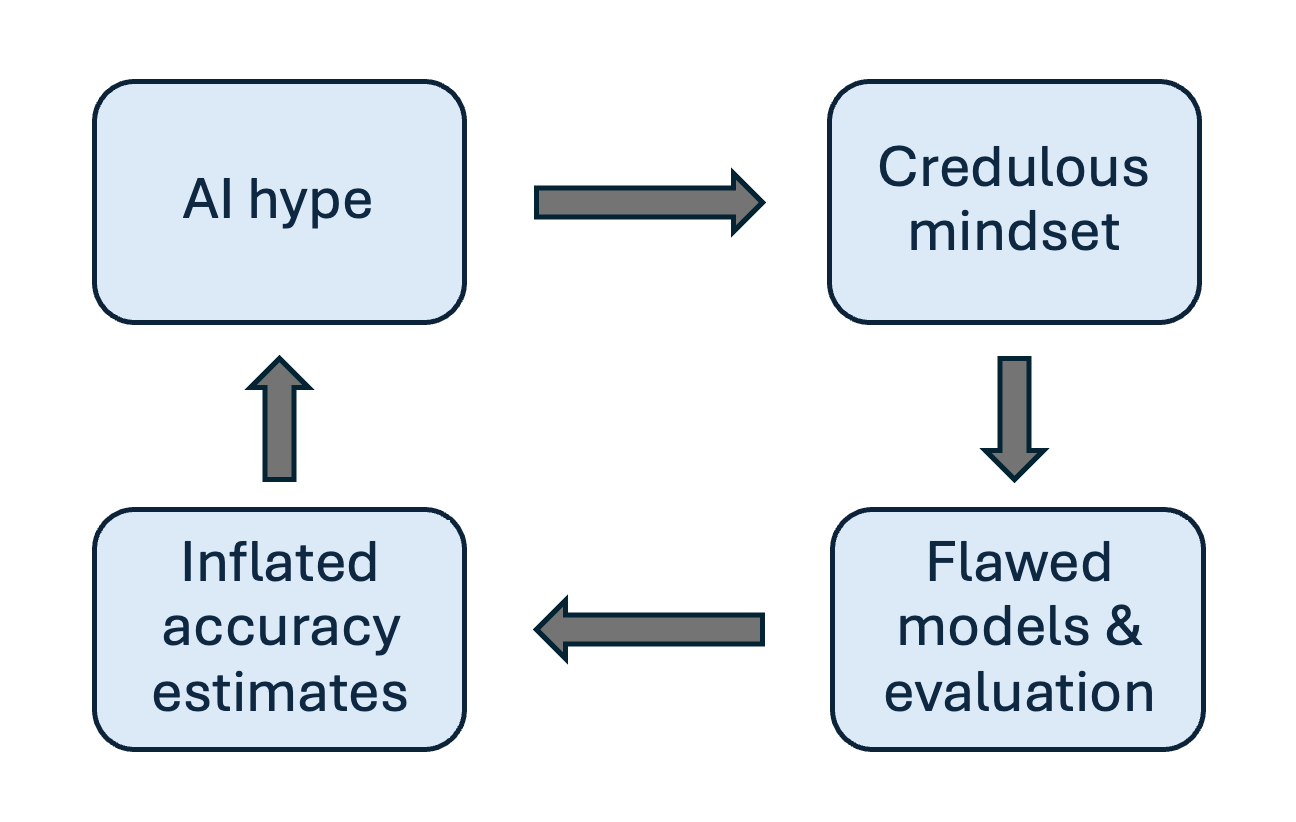
How AI hype leads to flawed research that fuels more hype
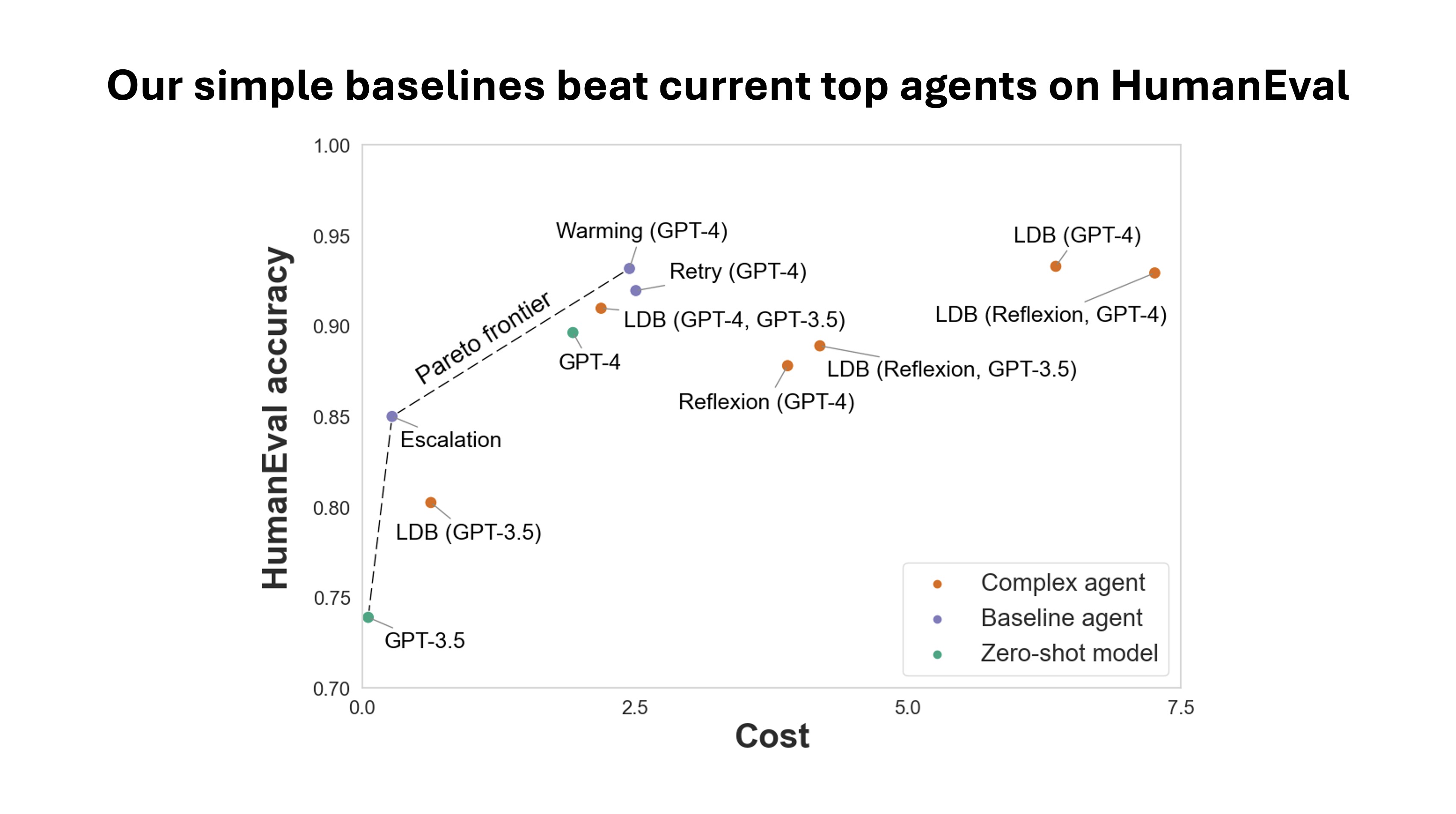
What spending $2,000 can tell us about evaluating AI agents